前言
有网友在交流群中询问,为什么字符串转成 UTF-8 字节数组后,值变了。0x80变成了0xC2 0x80("\x80"是字符串的16进制表示方式):.
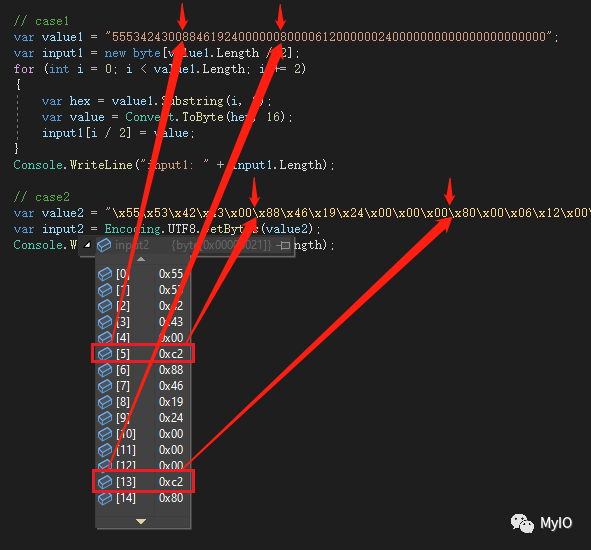
其实,这是因为 string 存储的是 UTF-16 编码的字符:

而使用Encoding.UTF8相当于将 UTF-16 编码转换成了 UTF-8 编码。
那它们到底有什么区别呢?
Unicode
Unicode 是一种国际编码标准,可用于各种平台以及各种语言和脚本。Unicode 标准定义了超过 110 万个码位。码位是一个整数值,通常使用语法U+xxxx来表示码位,其中 xxxx 是十六进制编码的整数值。
常用的表示 Unicode 码位的编码方式有:
-
UTF-8,将每个 Unicode 码位表示为一至四个字节的序列。 -
UTF-16,将每个 Unicode 码位表示为一至两个 16 位整数的序列。
因此,上例的\x80实际上表示的 Unicode 码位U+0080。
UTF-8
UTF-8可以使用一个字节对应 Unicode 码位字符串,而通常 Unicode 码位是用U+xxxx 两个字节表示的,为了和Unicode 码位进行对应,它进行了如下设定:
-
字符 U+0000 到 U+007F 使用一个字节对应,这意味着 ASCII 字符 和 UTF-8 具有相同的编码
-
所有字符 > U+007F 都编码为几个字节的组合,每个字节都设置了最高有效位,这意味着原来一个字节会拆分成多个字节

xxx代表二进制数值。最右边的 x 位是最低有效位。
因此,上例的\x80转化成 UTF-8 编码,实际值位于第 2 行110xxxxx 10xxxxxx。
Demo
根据上面的规则,我们可以自己验证上例的\x80如何转化成 UTF-8 编码的:
var utf16 = Convert.ToByte("80", 16);
Console.WriteLine("UTF-16:"+Convert.ToString(utf16, 2));
byte low = (byte)(Convert.ToByte("10000000", 2) + (utf16 & Convert.ToByte("00111111", 2)));
byte high = (byte)(Convert.ToByte("11000000", 2) + (utf16 >> 6));
Console.WriteLine("UTF-8:" + Convert.ToString(high, 16) + " " + Convert.ToString(low, 16));
Console.WriteLine("UTF-8:" + Convert.ToString(high, 2) + " " + Convert.ToString(low, 2));
-
保留 6 位低有效位, 组合成 10xxxxxx格式 -
保留 2 位高有效位, 组合成 110xxxxx格式
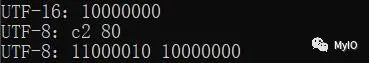
结论
通过上图可以看出,\x80低有效位都是 0,组合成10xxxxxx格式后,刚好也等于10000000(0x80)。造成了误解,以为数据被修改,其实是改变了编码导致的。
