场景:做为一个码农,大部分都集中在一二线城市,所以租房也就无可避免,面对如今五花八门的租房信息,往往很难找到合适的房子。而如今的这些租房软件,大部分也都被中介、广告等给占据了。除了去中介公司,感觉再也找不到合适的房子,但是面对50%的中介费,很大程度上也难以忍受。偶然之间听朋友说到可以去豆瓣看看,然后我就试着去寻找一下,结果发现豆瓣讨论组的信息太过杂乱,先不说房源的好坏,光是找合适位置的帖子就得翻好久。。。.
需求:所以,综上场景所述,就写了个简单的爬虫来爬取需要的位置以及最新发布的一些房源帖子。这里实现比较简单,同样豆瓣也有做一些防爬处理(IP访问次数等),而我并不是为了获取更多的信息而爬取,只是为了方便。所以既没有多线程处理,也没有做反防爬。每次获取的信息也足够看了,不行的话就等第二天再看呗。
开发环境:.NET Framework版本:4.5开发工具:Visual Studio 2013实现代码:private readonly string douBanUrl = "https://www.douban.com/group/search?cat=1019&sort=time";bool isStop = false;public FormCrawler(){InitializeComponent();}private void btn_start_Click(object sender, EventArgs e){if (string.IsNullOrWhiteSpace(txt_city.Text)){MessageBox.Show("请输入城市!");return;}if (string.IsNullOrWhiteSpace(txt_keys.Text)){MessageBox.Show("请输入关键字!");return;}//初始化控件btn_start.Enabled = false;btn_stop.Enabled = true;listView1.Items.Clear();progressBar1.Value = 0;List<string> groups = GetGroupUrls();progressBar1.Maximum = groups.Count;Task.Run(() =>{GetHouseInfo(groups);this.BeginInvoke(new Action(() =>{btn_start.Enabled = true;btn_stop.Enabled = false;}));});}private void btn_stop_Click(object sender, EventArgs e){isStop = true;btn_start.Enabled = true;btn_stop.Enabled = false;progressBar1.Value = progressBar1.Maximum;}private void listView1_MouseDoubleClick(object sender, MouseEventArgs e){ListView.SelectedListViewItemCollection selectItem = listView1.SelectedItems;if (selectItem.Count > 0){Process.Start(selectItem[0].SubItems[1].Text);}}
/// <summary>/// 获取前100个讨论组/// </summary>/// <returns></returns>private List<string> GetGroupUrls(){List<string> groupUrls = new List<string>();int pageSize = 20;//豆瓣每页显示20个讨论组string groupUrl = string.Empty;for (int groupNum = 0; groupNum <= 80; groupNum += pageSize){if (isStop) break;groupUrl = string.Format(douBanUrl + "&q={0}&start={1}", HttpUtility.UrlEncode(txt_city.Text + "租房", Encoding.UTF8), groupNum);string text = HttpUtil.HttpGet(groupUrl);if (!string.IsNullOrWhiteSpace(text)){Regex reg = new Regex(@"(?is)(?<=<div\sclass=""pic""[^>]*?>).*?(?=</div>)");MatchCollection matchs = reg.Matches(text);for (int i = 0; i < matchs.Count; i++){if (matchs[i].Success){Regex regHref = new Regex("(?<=href\\s*=\\s*\")\\S+(?<!\")");string href = regHref.Match(matchs[i].Value).Value;groupUrls.Add(href);}}}}return groupUrls;}/// <summary>/// 获取讨论组内符合条件的房源/// </summary>/// <param name="urls"></param>private void GetHouseInfo(List<string> urls){for (int u = 0; u < urls.Count; u++){if (isStop) break;this.BeginInvoke(new Action(() =>{progressBar1.Value++;}));string text = HttpUtil.HttpGet(urls[u] + "/discussion?start=");Regex regex = new Regex(@"(?is)(?<=<tr\sclass=""""[^>]*?>).*?(?=</tr>)");MatchCollection matchs = regex.Matches(text);for (int i = 0; i < matchs.Count; i++){if (matchs[i].Success){#region 匹配时间Regex regDate = new Regex(@"(?is)(?<=<td\snowrap=""nowrap""\sclass=""time""[^>]*?>).*?(?=</td>)");Match matchDate = regDate.Match(matchs[i].Value);if (!matchDate.Success){continue;}string time = matchDate.Value;DateTime dtTemp = new DateTime();if (!DateTime.TryParse(time, out dtTemp)){time = time.Insert(0, DateTime.Now.Year + "-");dtTemp = Convert.ToDateTime(time);}if (dtTemp < dateTimePicker1.Value.Date){continue;}#endregion#region 获取标题Regex regTitle = new Regex("(?<=title\\s*=\\s*\")\\s*\\S*(?<!\")");Match matchTitle = regTitle.Match(matchs[i].Value);if (matchTitle.Success){string title = matchTitle.Value;#region 匹配标题bool isContain = false;string[] keys = txt_keys.Text.Split('*');foreach (string key in keys){if (matchTitle.Value.Contains(key)){isContain = true;}}#endregionif (isContain){//获取链接Regex regHref = new Regex("(?<=href\\s*=\\s*\")\\s*\\S*(?<!\")");string href = regHref.Match(matchs[i].Value).Value;AddUI(title, href, time);}}#endregion}}}}private void AddUI(string title, string href, string time){if (this.InvokeRequired){this.BeginInvoke(new Action(() => AddUI(title, href, time)));}else{ListViewItem lvitem = new ListViewItem(new string[3] { title, href, time });listView1.Items.Add(lvitem);}}
实现效果:
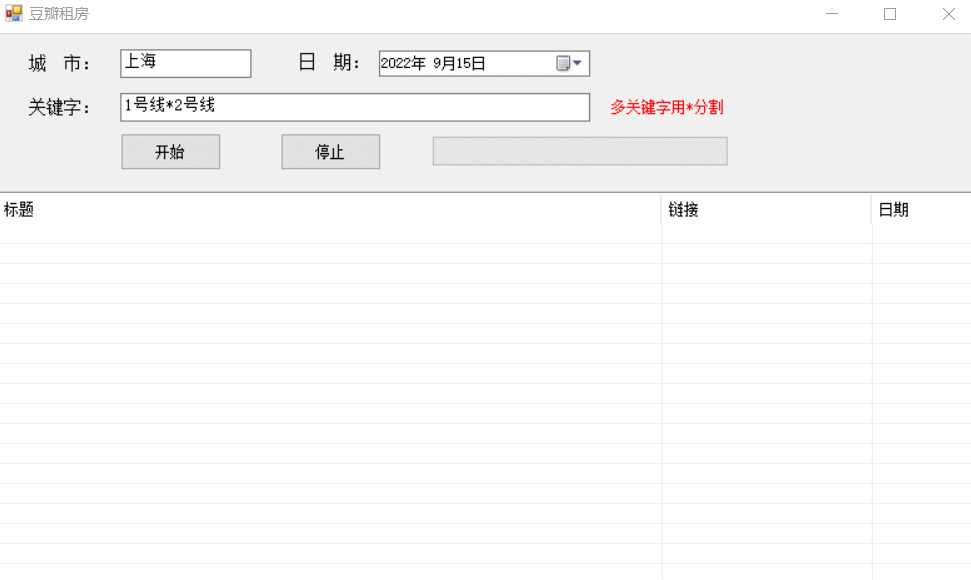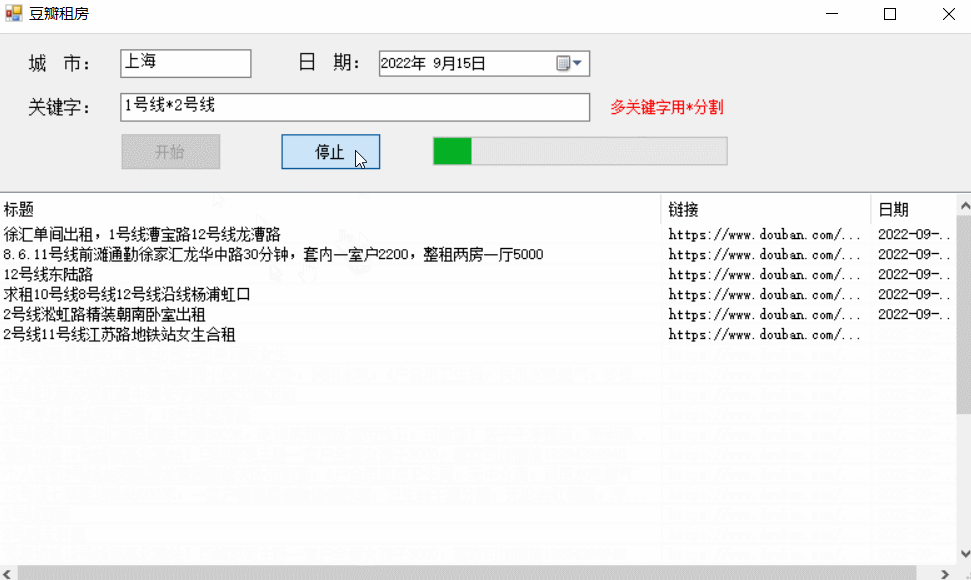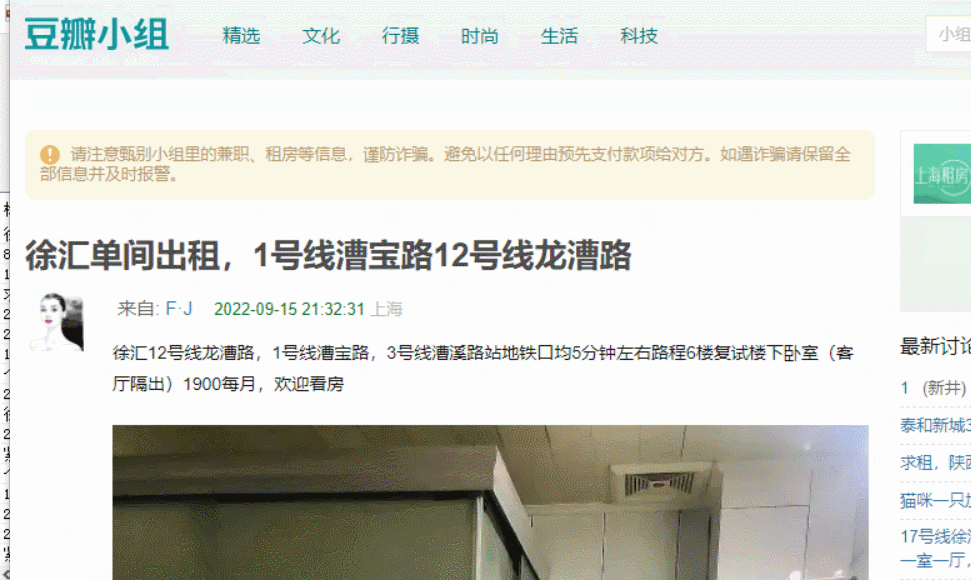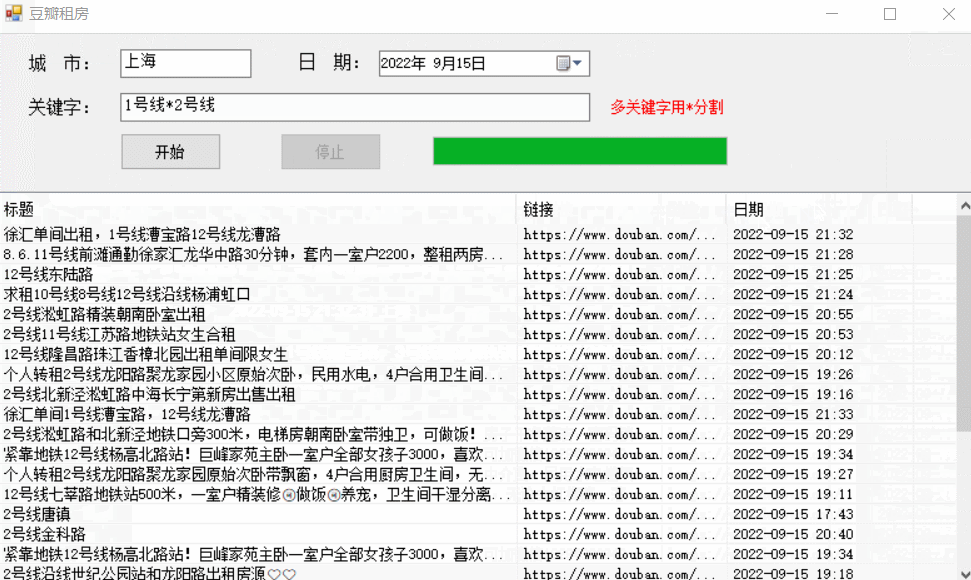
代码解析:主要是使用了HttpGet来获取链接的网页信息,然后使用正则匹配我们的需求数据。每次只访问100个讨论组,每个讨论组内获取第一页的帖子信息。如果不使用代理ip或者其他反防爬机制的话,基本上这个软件每天只使用一次就达到上限了(获取到的数据为空等);要是没有合适的帖子的话,可以第二天再查找一下。
本代码只用于学习交流,请勿用于非法用途。
