先来个.*?的解释吧
. : 单个任意字符
* : 重复多次、贪婪匹配。注意*在正则中不是任意字符,而是一个限定限定出现的次数
? : 出现1次或者0次、非贪婪匹配.
提取一个字符串的中文
-
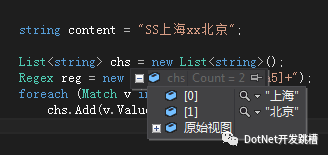
string content = "SS上海xx北京"; -
List<string> chs = new List<string>(); -
Regex reg = new Regex("[\u4e00-\u9fa5]+"); -
foreach (Match v in reg.Matches(content)) -
chs.Add(v.Value);
效果如下:
正则表达式拆分字符串
-
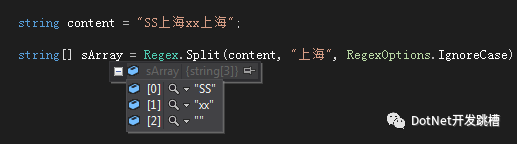
string content = "SS上海xx上海"; -
string[] sArray = Regex.Split(content, "上海", RegexOptions.IgnoreCase);
这个很简单,效果如下:
他可以根据一个字符串去拆分,后面的参数是忽略大小写
例子2:根据一个标签拆分字符串
拆分"aa<em>哈哈</em>bb<em>嘻嘻</em>cc"成 aa,bb,cc
-
string[] str = Regex.Split(title, @"<em>.*?</em>");
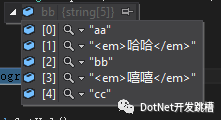
拆分成aa,<em>哈哈</em>,bb,<em>嘻嘻</em,cc
-
string[] str2 = Regex.Split(title,"(<em>.*?</em>)");
效果如下:
其实很简单就是正则里边加一个()括起来就能得到它本身了
例子3:根据中文拆分字符串
-
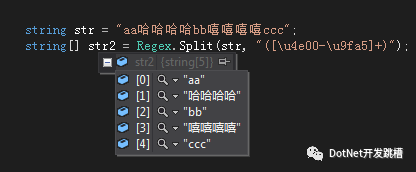
string str = "aa哈哈哈哈bb嘻嘻嘻嘻ccc"; -
string[] str2 = Regex.Split(str, "([\u4e00-\u9fa5]+)");
效果如下:
正则表达式替换字符串
-
string content = "SS重庆xx"; -
content = Regex.Replace(content, "重庆", "<font>重庆</font>", RegexOptions.IgnoreCase);

正则表达式提取字符串
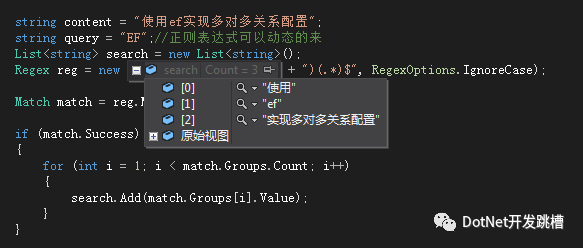
例如有一个字符串:"使用ef实现多对多关系配置"
我想使用ef作为一个关键字进行提取,提取ef的左边,ef本身,ef的右边。
我们就可以写一个正则表达式来提取: Regex reg = new Regex("^(.*)(ef)(.*)$", RegexOptions.IgnoreCase);
正则表达式中用()将要提取的内容括起来,然后就可以通过Match的Groups属性来得到所有的提取元素,注意Groups的序号是从1开始的,0有特殊含义
-
string content = "使用ef实现多对多关系配置"; -
string query = "EF";//正则表达式可以动态的来 -
List<string> search = new List<string>(); -
Regex reg = new Regex("^(.*)(" + query + ")(.*)$", RegexOptions.IgnoreCase); -
Match match = reg.Match(content); -
if (match.Success) -
{ -
for (int i = 1; i < match.Groups.Count; i++) -
{ -
search.Add(match.Groups[i].Value); -
} -
}
效果如下:
正则表达式写起来很简单就是头冷。
