这几年的AI的发展,使得文字识别难度大大降低、精度大大的提高。百度飞浆就是一个非常好的AI框架,而且是开源的。.
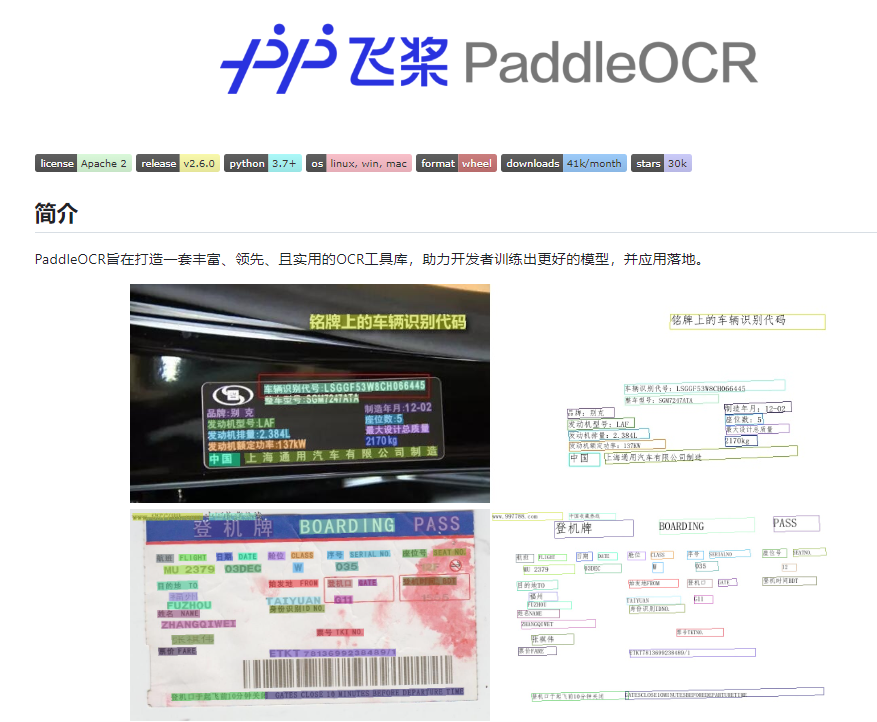
我们利用百度飞浆就能快速简单的实现文字识别功能,几行代码就可以集成。
其中百度飞浆的PaddleOCR,就是专门针对文本识别的开发套件,包含的功能有:文本失败、文本检测、表格识别,支持中英文数字组合的识别、竖排、长文本识别,而且还针对小图做了优化,大大提升准确率。
下面我们一起来看看,如何使用百度飞浆实现文字识别:
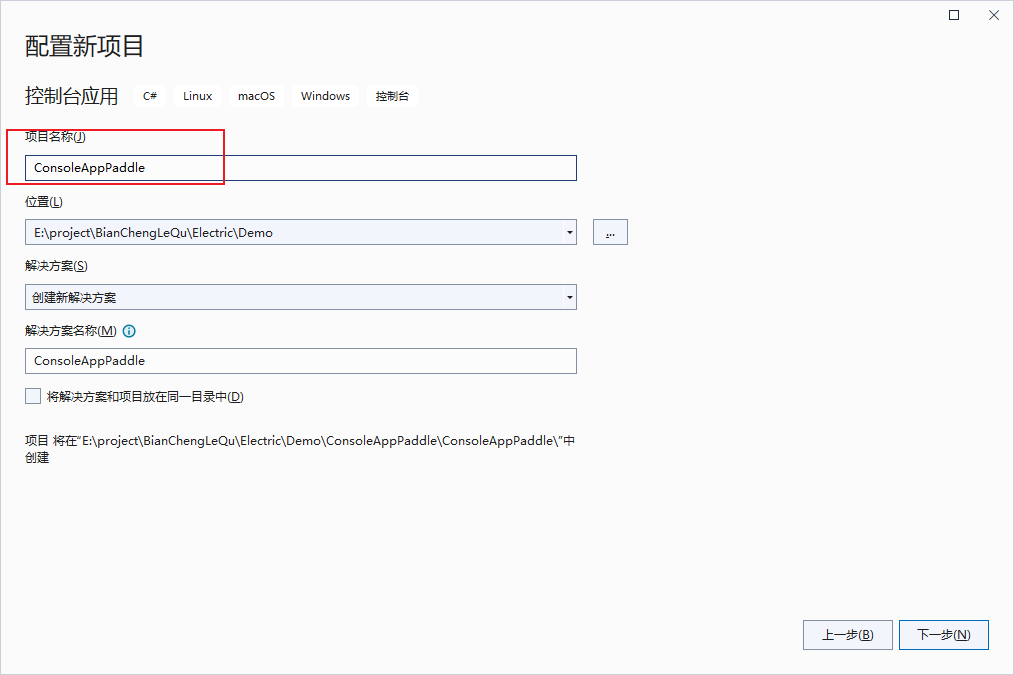
一、新建项目
新建一个控制台项目。
二、安装依赖包
通过NuGet,安装依赖包:PaddleOCRSharp。
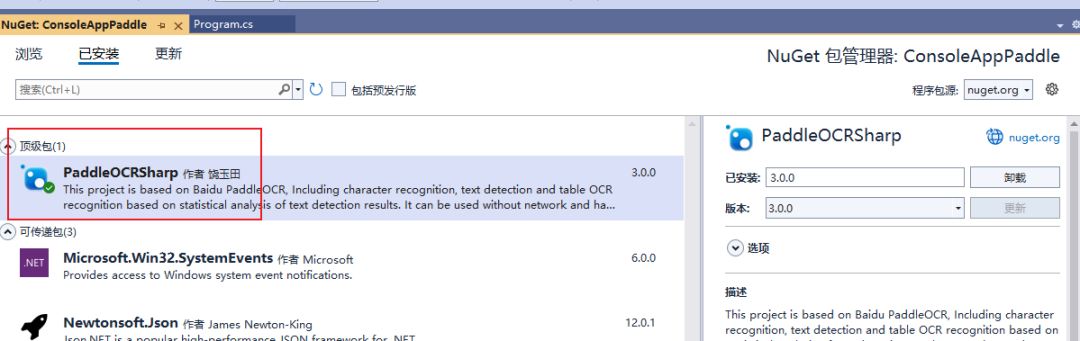
PaddleOCRSharp是Github的开源项目,是基于百度飞浆C++代码封装的.Net类库,其中支持PaddleOCR版本是release2.5。如果大家需要最新版本,或者其他模型,也可以自行封装。
项目地址:https://github.com/raoyutian/PaddleOCRSharp
安装依赖后,我们就可以看到很多dll库。
三、编写识别代码
识别图片的文字,并打印,代码如下:
using PaddleOCRSharp;PaddleOCREngine engine;//中英文模型V3模型OCRModelConfig config = null;//OCR参数OCRParameter oCRParameter = new OCRParameter();oCRParameter.cpu_math_library_num_threads = 6;//预测并发线程数oCRParameter.enable_mkldnn = true;//是否使用mkldnn模型oCRParameter.cls = false; //是否执行文字方向分类oCRParameter.use_angle_cls = false;//是否开启方向检测oCRParameter.det_db_score_mode = true;//是否使用多段线,即文字区域是用多段线还是用矩形,oCRParameter.det_db_unclip_ratio = 1.6f;oCRParameter.max_side_len = 2000;//初始化OCR引擎engine = new PaddleOCREngine(config, oCRParameter);var imagebyte = File.ReadAllBytes("1.png");OCRResult ocrResult = engine.DetectText(imagebyte);Console.WriteLine(ocrResult.Text);
四、执行效果如下
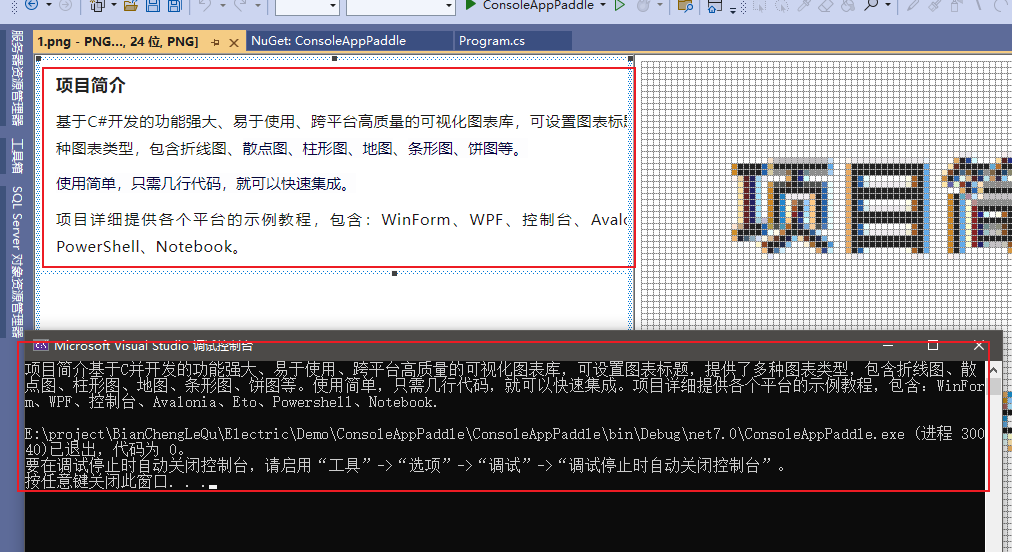
识别速度、效果还是非常好的。
