数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。而且,在事务的并发操作中可能会出现脏读,不可重复读,幻读。下面通过事例一一阐述它们的概念与联系。
Read uncommitted
读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。.
事例:老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交。
分析:实际程序员这个月的工资还是3.6万,但是程序员看到的是3.9万。他看到的是老板还没提交事务时的数据。这就是脏读。
Read committed
读提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他买单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
分析:这就是读提交,若有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。
Repeatable read
重复读,就是在开始读取数据(事务开启)时,不再允许修改操作
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
分析:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
什么时候会出现幻读?
事例:程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现花了1.2万元,似乎出现了幻觉,这就是幻读。
那怎么解决幻读问题?Serializable
Serializable 序列化
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
四种隔离级别可能导致的问题:
1、Serializable (串行化):最严格的级别,事务串行执行,资源消耗最大;
2、REPEATABLE READ(重复读) :保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据。避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”,但是带来了更多的性能损失。
3、READ COMMITTED (提交读):大多数主流数据库的默认事务等级,保证了一个事务不会读到另一个并行事务已修改但未提交的数据,避免了“脏读取”,但不能避免“幻读”和“不可重复读取”。该级别适用于大多数系统。
4、Read Uncommitted(未提交读) :事务中的修改,即使没有提交,其他事务也可以看得到,会导致“脏读”、“幻读”和“不可重复读取”。
通俗解释:
脏读:所谓的脏读,其实就是读到了别的事务回滚前的脏数据。比如事务B执行过程中修改了数据X,在未提交前,事务A读取了X,而事务B却回滚了,这样事务A就形成了脏读。
也就是说,当前事务读到的数据是别的事务想要修改成为的但是没有修改成功的数据。
不可重复读:事务A首先读取了一条数据,然后执行逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读了。
也就是说,当前事务先进行了一次数据读取,然后再次读取到的数据是别的事务修改成功的数据,导致两次读取到的数据不匹配,也就照应了不可重复读的语义。
幻读:事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。
也就是说,当前事务读第一次取到的数据比后来读取到数据条目不一致。
mysql默认隔离级别
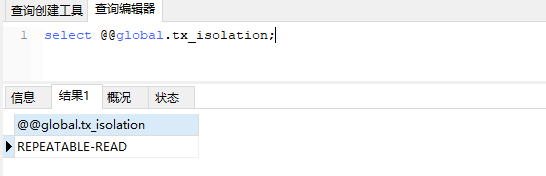
1.查询mysql全局事务隔离级别
select @@global.tx_isolation;
2.查询当前会话事务隔离级别
select @@tx_isolation;
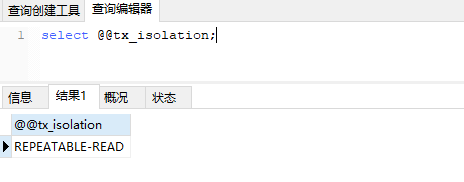
mysql默认事务隔离级别为重复读REPEATABLE-READ 可以避免脏读,不可重复读,不可避免幻读
常看当前数据库的事务隔离级别: show variables like 'tx_isolation';
设置事务隔离级别:set tx_isolation='REPEATABLE-READ';
Mysql默认的事务隔离级别是可重复读,用Spring开发程序时,如果不设置隔离级别默认用Mysql设置的隔
离级别,如果Spring设置了就用已经设置的隔离级别
为什么MySQL的默认隔离离别是RR?
binlog的格式也有三种:statement,row,mixed。设置为statement格式,binlog记录的是SQL的原文。又因为MySQL在主从复制的过程是通过binlog进行数据同步,如果设置为读已提交(RC)隔离级别,当出现事务乱序的时候,就会导致备库在 SQL 回放之后,结果和主库内容不一致。
比如:
CREATE TABLE t (
a int(11) DEFAULT NULL,
b int(11) DEFAULT NULL,
PRIMARY KEY a (a),
KEY b(b)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
insert into t1 values(10,666),(20,233);

在读已提交(RC)隔离级别下,两个事务执行完后,数据库的两条记录就变成了(30,666)、(20,666)。这两个事务执行完后,binlog也就有两条记录,因为事务binlog用的是statement格式,事务2先提交,因此update t set b=666 where b=233优先记录,而update t set a=30 where b=666记录在后面。
当bin log同步到从库后,执行update t set b=666 where b=233和update t set a=30 where b=666记录,数据库的记录就变成(30,666)、(30,666),这时候主从数据不一致啦。
因此MySQL的默认隔离离别选择了RR而不是RC。RR隔离级别下,更新数据的时候不仅对更新的行加行级锁,还会加间隙锁(gap lock)。事务2要执行时,因为事务1增加了间隙锁,就会导致事务2执行被卡住,只有等事务1提交或者回滚后才能继续执行。
并且,MySQL还禁止在使用statement格式的binlog的情况下,使用READ COMMITTED作为事务隔离级别。
我们的数据库隔离级别最后选的是读已提交(RC)。
那为什么MySQL官方默认隔离级别是RR,而有些大厂选择了RC作为默认的隔离级别呢?
- 提升并发
RC 在加锁的过程中,不需要添加Gap Lock和 Next-Key Lock 的,只对要修改的记录添加行级锁就行了。因此RC的支持的并发度比RR高得多,
- 减少死锁
正是因为RR隔离级别增加了Gap Lock和 Next-Key Lock 锁,因此它相对于RC,更容易产生死锁。
解决幻读
MVCC加上间隙锁的方式
(1)在快照读情况下,mysql通过mvcc来避免幻读。
(2)在当前读情况下,mysql通过next-key(next-key锁是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁)来避免幻读。锁住某个条件下的数据不能更改。
可重复读隔离级别下MySQL是如何解决幻读问题的
https://my.oschina.net/u/4129361/blog/3048941
https://blog.csdn.net/aaa821/article/details/81017704
参考: https://www.cnblogs.com/ubuntu1/p/8999403.html
http://blog.itpub.net/26736162/viewspace-2638951/
https://www.cnblogs.com/imfx/p/11202824.html
https://mp.weixin.qq.com/s/7-go30yu8k48sY-usu2V4Q
