引子
.NET 6 开始初步引入 PGO。PGO 即 Profile Guided Optimization,通过收集运行时信息来指导 JIT 如何优化代码,相比以前没有 PGO 时可以做更多以前难以完成的优化。
下面我们用 .NET 6 的 nightly build 版本 6.0.100-rc.1.21377.6 来试试新的 PGO。.
PGO 工具
.NET 6 提供了静态 PGO 和动态 PGO。前者通过工具收集 profile 数据,然后应用到下一次编译当中指导编译器如何进行代码优化;后者则直接在运行时一边收集 profile 数据一边进行优化。
另外由于从 .NET 5 开始引入了 OSR(On Stack Replacement),因此可以在运行时替换正在运行的函数,允许将正在运行的低优化代码迁移到高优化代码,例如替换一个热循环中的代码。
分层编译和 PGO
.NET 从 Core 3.1 开始正式引入了分层编译(Tiered Compilation),程序启动时 JIT 首先快速生成低优化的 tier 0 代码,由于优化代价小,因此 JIT 吞吐量很高,可以改善整体的延时。
然后随着程序运行,对多次调用的方法进行再次 JIT 产生高优化的 tier 1 代码,以提升程序的执行效率。
但是这么做对于程序的性能几乎没有提升,只是改善了延时,降低首次 JIT 的时间,却反而可能由于低优化代码导致性能倒退。因此我个人通常在开发客户端类程序的时候会关闭分层编译,而在开发服务器程序时开启分层编译。
然而 .NET 6 引入 PGO 后,分层编译的机制将变得非常重要。
由于 tier 0 的代码是低优化代码,因此更能够收集到完整的运行时 profile 数据,指导 JIT 做更全面的优化。
为什么这么说?
例如在 tier 1 代码中,某方法 B 被某方法 A 内联(inline),运行期间多次调用方法 A 后收集到了 profile 将只包含 A 的信息,而没有 B 的信息;又例如在 tier 1 代码中,某循环被 JIT 做了 loop cloning,那此时收集到的 profile 则是不准确的。
因此为了发挥 PGO 的最大效果,我们不仅需要开启分层编译,还需要给循环启用 Quick Jit 在一开始生成低优化代码。
进行优化
前面说了这么多,那 .NET 6 的 PGO 到底应该如何使用,又会如何对代码优化产生影响呢?这里举个例子。
测试代码
新建一个 .NET 6 控制台项目 PgoExperiment,考虑有如下代码:
interface IGenerator
{
bool ReachEnd { get; }
int Current { get; }
bool MoveNext();
}
abstract class IGeneratorFactory
{
public abstract IGenerator CreateGenerator();
}
class MyGenerator : IGenerator
{
private int _current;
public bool ReachEnd { get; private set; }
public int Current { get; private set; }
public bool MoveNext()
{
if (ReachEnd)
{
return false;
}
_current++;
if (_current > 1000)
{
ReachEnd = true;
return false;
}
Current = _current;
return true;
}
}
class MyGeneratorFactory : IGeneratorFactory
{
public override IGenerator CreateGenerator()
{
return new MyGenerator();
}
}
我们利用 IGeneratorFactory 产生 IGenerator,同时分别提供对应的一个实现 MyGeneratorFactory 和 MyGenerator。注意实现类并没有标注 sealed 因此 JIT 并不知道是否能做去虚拟化(devirtualization),于是生成的代码会老老实实查虚表。
然后我们编写测试代码:
[MethodImpl(MethodImplOptions.NoInlining)]
int Test(IGeneratorFactory factory)
{
var generator = factory.CreateGenerator();
var result = 0;
while (generator.MoveNext())
{
result += generator.Current;
}
return result;
}
var sw = Stopwatch.StartNew();
var factory = new MyGeneratorFactory();
for (var i = 0; i < 10; i++)
{
sw.Restart();
for (int j = 0; j < 1000000; j++)
{
Test(factory);
}
sw.Stop();
Console.WriteLine($"Iteration {i}: {sw.ElapsedMilliseconds} ms.");
}
你可能会问为什么不用 BenchmarkDotNet,因为这里要测试出 分层编译和 PGO 前后的区别,因此不能进行所谓的“预热”。
进行测试
测试环境:
-
CPU:2vCPU Intel(R) Xeon(R) Platinum 8171M CPU @ 2.60GHz
-
内存:4G
-
系统:Ubuntu 20.04.2 LTS
-
程序运行配置:Release
不使用 PGO
首先采用默认参数运行:
dotnet run -c Release
得到结果:
Iteration 0: 740 ms.
Iteration 1: 648 ms.
Iteration 2: 687 ms.
Iteration 3: 639 ms.
Iteration 4: 643 ms.
Iteration 5: 641 ms.
Iteration 6: 641 ms.
Iteration 7: 639 ms.
Iteration 8: 644 ms.
Iteration 9: 643 ms.
Mean = 656.5ms
你会发现 Iteration 0 用时比其他都要长一点,这符合预期,因为一开始执行的是 tier 0 的低优化代码,然后随着调用次数增加,JIT 重新生成 tier 1 的高优化代码。
然后我们关闭分层编译看看会怎么样:
dotnet run -c Release /p:TieredCompilation=false
得到结果:
Iteration 0: 677 ms.
Iteration 1: 669 ms.
Iteration 2: 677 ms.
Iteration 3: 680 ms.
Iteration 4: 683 ms.
Iteration 5: 689 ms.
Iteration 6: 677 ms.
Iteration 7: 685 ms.
Iteration 8: 676 ms.
Iteration 9: 673 ms.
Mean = 678.6ms
这下就没有区别了,因为一开始生成的就是 tier 1 的高优化代码。
我们看看 JIT dump:
push rbp
push r14
push rbx
lea rbp,[rsp+10h]
; factory.CreateGenerator()
mov rax,[rdi]
mov rax,[rax+40h]
call qword ptr [rax+20h]
mov rbx,rax
; var result = 0
xor r14d,r14d
; if (generator.MoveNext())
mov rdi,rbx
mov r11,7F3357AE0008h
mov rax,7F3357AE0008h
call qword ptr [rax]
test eax,eax
je short LBL_1
LBL_0:
; result += generator.Current;
mov rdi,rbx
mov r11,7F3357AE0010h
mov rax,7F3357AE0010h
call qword ptr [rax]
add r14d,eax
; if (generator.MoveNext())
mov rdi,rbx
mov r11,7F3357AE0008h
mov rax,7F3357AE0008h
call qword ptr [rax]
test eax,eax
jne short LBL_0
LBL_1:
; return result;
mov eax,r14d
pop rbx
pop r14
pop rbp
ret
我用注释标注出了生成的代码中关键地方对应的 C# 写法,还原成 C# 代码大概是这个样子:
var generator = factory.CreateGenerator();
var result = 0;
do
{
if (generator.MoveNext())
{
result += generator.Current;
}
else
{
return result;
}
} while(true);
这里有不少有趣的地方:
-
while循环被优化成了do-while循环,做了一次 loop inversion,以此来节省一次循环 -
generator.CreateGenerator、generator.MoveNext以及generator.Current完全没有被去虚拟化 -
因为没有去虚拟化,所以也难以内联
这已经是 tier 1 代码了,也就是目前阶段 RyuJIT(.NET 6 的 JIT 编译器)在不借助任何指示编译器的 Attribute 以及 PGO 所能生成的最大优化等级的代码。
使用 PGO
这一次我们先看看启用动态 PGO 能得到怎样的结果。
为了使用动态 PGO,现阶段需要设置一些环境变量。
export DOTNET_ReadyToRun=0 # 禁用 AOT
export DOTNET_TieredPGO=1 # 开启分层 PGO
export DOTNET_TC_QuickJitForLoops=1 # 为循环启用 Quick Jit
然后运行即可:
dotnet run -c Release
得到如下结果:
Iteration 0: 349 ms.
Iteration 1: 190 ms.
Iteration 2: 188 ms.
Iteration 3: 189 ms.
Iteration 4: 190 ms.
Iteration 5: 190 ms.
Iteration 6: 189 ms.
Iteration 7: 188 ms.
Iteration 8: 191 ms.
Iteration 9: 189 ms.
Mean = 205.3ms
得到了惊人的性能提升,只用了先前的 31% 的时间,相当于性能提升 322%。
然后我们试试静态 PGO + AOT 编译,AOT 负责在编译时预先生成优化后的代码。
为了使用静态 PGO,我们需要安装 dotnet-pgo 工具生成静态 PGO 数据,由于正式版尚未发布,因此需要添加如下 nuget 源
<configuration>
<packageSources>
<add key="dotnet-public" value="https://pkgs.dev.azure.com/dnceng/public/_packaging/dotnet-public/nuget/v3/index.json" />
<add key="dotnet-tools" value="https://pkgs.dev.azure.com/dnceng/public/_packaging/dotnet-tools/nuget/v3/index.json" />
<add key="dotnet-eng" value="https://pkgs.dev.azure.com/dnceng/public/_packaging/dotnet-eng/nuget/v3/index.json" />
<add key="dotnet6" value="https://pkgs.dev.azure.com/dnceng/public/_packaging/dotnet6/nuget/v3/index.json" />
<add key="dotnet6-transport" value="https://pkgs.dev.azure.com/dnceng/public/_packaging/dotnet6-transport/nuget/v3/index.json" />
</packageSources>
</configuration>
安装 dotnet-pgo 工具:
dotnet tool install dotnet-pgo --version 6.0.0-* -g
先运行程序采集 profile:
export DOTNET_EnableEventPipe=1
export DOTNET_EventPipeConfig=Microsoft-Windows-DotNETRuntime:0x1F000080018:5
export DOTNET_EventPipeOutputPath=trace.nettrace # 追踪文件输出路径
export DOTNET_ReadyToRun=0 # 禁用 AOT
export DOTNET_TieredPGO=1 # 启用分层 PGO
export DOTNET_TC_CallCounting=0 # 永远不产生 tier 1 代码
export DOTNET_TC_QuickJitForLoops=1
export DOTNET_JitCollect64BitCounts=1
dotnet run -c Release
等待程序运行完成,我们会得到一个 trace.nettrace 文件,里面包含了追踪数据,然后利用 dotnet-pgo 工具产生 PGO 数据。
dotnet-pgo create-mibc -t trace.nettrace -o pgo.mibc
至此我们就得到了一个 pgo.mibc,里面包含了 PGO 数据。
然后我们使用 crossgen2,在 PGO 数据的指导下对代码进行 AOT 编译:
dotnet publish -c Release -r linux-x64 /p:PublishReadyToRun=true /p:PublishReadyToRunComposite=true /p:PublishReadyToRunCrossgen2ExtraArgs=--embed-pgo-data%3b--mibc%3apgo.mibc
你可能会觉得这一系列步骤里面不少参数和环境变量都非常诡异,自然也是因为目前正式版还没有发布,因此名称和参数什么的都还没有规范化。
编译后我们运行编译后代码:
cd bin/Release/net6.0/linux-x64/publish
./PgoExperiment
得到如下结果:
Iteration 0: 278 ms.
Iteration 1: 185 ms.
Iteration 2: 186 ms.
Iteration 3: 187 ms.
Iteration 4: 184 ms.
Iteration 5: 187 ms.
Iteration 6: 185 ms.
Iteration 7: 183 ms.
Iteration 8: 180 ms.
Iteration 9: 186 ms.
Mean = 194.1ms
相比动态 PGO 而言,可以看出第一次用时更小,因为不需要经过 profile 收集后重新 JIT 的过程。
我们看看 PGO 数据指导下产生了怎样的代码:
push rbp
push r15
push r14
push r12
push rbx
lea rbp,[rsp+20h]
; if (factory.GetType() == typeof(MyGeneratorFactory))
mov rax,offset methodtable(MyGeneratorFactory)
cmp [rdi],rax
jne near ptr LBL_11
; IGenerator generator = new MyGenerator()
mov rdi,offset methodtable(MyGenerator)
call CORINFO_HELP_NEWSFAST
mov rbx,rax
LBL_0:
; var result = 0
xor r14d,r14d
jmp short LBL_4
LBL_1:
; if (generator.GetType() == typeof(MyGenerator))
mov rdi,offset methodtable(MyGenerator)
cmp r15,rdi
jne short LBL_6
; result += generator.Current
LBL_2:
mov r12d,[rbx+0Ch]
LBL_3:
add r14d,r12d
LBL_4:
; if (generator.GetType() == typeof(MyGenerator))
mov r15,[rbx]
mov rax,offset methodtable(MyGenerator)
cmp r15,rax
jne short LBL_8
; if (generator.ReachEnd)
mov rax,rbx
cmp byte ptr [rax+10h],0
jne short LBL_7
; generator._current++
mov eax,[rbx+8]
inc eax
mov [rbx+8],eax
; if (generator._current > 1000)
cmp eax,3E8h
jg short LBL_5
mov [rbx+0Ch],eax
jmp short LBL_2
LBL_5:
; ReachEnd = true
mov byte ptr [rbx+10h],1
jmp short LBL_10
LBL_6:
; result += generator.Current
mov rdi,rbx
mov r11,7F5C42A70010h
mov rax,7F5C42A70010h
call qword ptr [rax]
mov r12d,eax
jmp short LBL_3
LBL_7:
xor r12d,r12d
jmp short LBL_9
LBL_8:
; if (generator.MoveNext())
mov rdi,rbx
mov r11,7F5C42A70008h
mov rax,7F5C42A70008h
call qword ptr [rax]
mov r12d,eax
LBL_9:
test r12d,r12d
jne near ptr LBL_1
LBL_10:
; return true/false
mov eax,r14d
pop rbx
pop r12
pop r14
pop r15
pop rbp
ret
LBL_11:
; factory.CreateGenerator()
mov rax,[rdi]
mov rax,[rax+40h]
call qword ptr [rax+20h]
mov rbx,rax
jmp near ptr LBL_0
同样,我用注释标注出来了关键地方对应的 C# 代码,这里由于稍微有些麻烦因此就不在这里还原回大概的 C# 逻辑了。
同样,我们发现了不少有趣的地方:
-
通过类型测试判断
factory是否是MyGeneratorFactory、generator是否是MyGenerator-
如果是,则跳转到一个代码块,这里面将
IGeneratorFactory.CreateFactory、IGenerator.MoveNext以及IGenerator.Current全部去虚拟化,这也叫做 guarded devirtualization,并且全部进行了内联 -
否则跳转到一个代码块,这里面的代码等同于不开启 PGO 的 tier 1 代码
-
这里做了一次 loop cloning
-
-
while循环同样被优化成了do-while,做了一次 loop inversion
相比不开启 PGO 而言,显然优化幅度就大了很多。
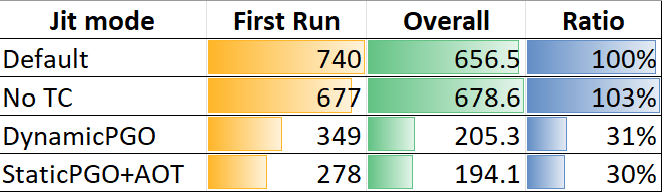
用一张图来对比首次运行、总体用时(毫秒)和比例(均为越低越好),从上至下分别是默认、关闭分层编译、动态 PGO、静态 PGO:
总结
有了 PGO 之后,之前的很多性能经验就不再有效。最典型的例如在用 List<T> 或者 Array 的时候 IEnumerable<T>.Where(pred).FirstOrDefault() 比 IEnumerable<T>.FirstOrDefault(pred) 快,这是因为 IEnumerable<T>.Where 在代码层面手动做了针对性的去虚拟化,而 FirstOrDefault<T> 没有。但是在 PGO 的辅助下,即使不需要手动编写针对性去虚拟化的代码也能成功去虚拟化,而且不仅仅局限于 List<T> 和 Array,对所有实现 IEnumerable<T> 的类型都适用。
借助 PGO 我们可以预见大幅度的执行效率提升。例如在 TE-benchmark 非官方测试的 plaintext mvc 中,对比第一次请求时间(毫秒,从运行程序开始计算,越低越好)、RPS(越高越好)和比例(越高越好)结果如下:

另外,PGO 在 .NET 6 中尚处于初步阶段,后续版本(.NET 7+)中将会带来更多基于 PGO 的优化。
至于其他的 JIT 优化方面,.NET 6 同样做了大量的改进,例如更多的 morphing pass、jump threading、loop inversion、loop alignment、loop cloning 等等,并且优化了 LSRA 和 register heuristic,以及解决了不少导致 struct 出现 stack spilling 的情况,以使其一直保持在寄存器中。但是尽管如此,RyuJIT 在优化方面仍有很长的路要走,例如 loop unrolling、forward subsitituion 以及包含关系条件的 jump threading 之类的优化 .NET 6 目前并不具备,这些优化将会在 .NET 7 或者之后到来。
