【导读】上一篇我们讨论到获取将要执行的迁移操作,到这一步为止,针对所有数据库都通用,在此之后需要生成SQL脚本对于不同数据库将有不同差异,我们一起来瞅一瞅。.
SQLite脚本生成差异
在上一篇拿到的迁移操作类即MigrationOperation为执行所有其他操作类的父类,比如添加列操作(AddColumnOperation),修改列操作(AlterColumnOperation)、创建表操作(CreateTableOperation)等等,我们知道SQLite不支持修改列,所以我们需要去除列修改操作,代码如下:
// Sqlite不支持修改操作,所以需过滤修改迁移操作
var operations = migrationOperations.Except(migrationOperations.Where(o => o is AlterColumnOperation)).ToList();
if (!operations.Any())
{
return;
}
然后获取生成SQL脚本接口,拿到执行操作命令类里面的脚本文本即可
var migrationsSqlGenerator = context.GetService<IMigrationsSqlGenerator>();
var commandList = migrationsSqlGenerator.Generate(operations);
if (!commandList.Any())
{
return;
}
var sqlScript = string.Concat(commandList.Select(c => c.CommandText));
if (string.IsNullOrEmpty(sqlScript))
{
return;
}
MySQL脚本生成差异
因为我们可能会修改主键,此时Pomelo.EntityFrameworkCore.MySql使用的方式则是创建一个临时存储过程,先删除主键,然后则执行完相关脚本后,最后重建主键,然后删除临时存储过程,临时存储过程如下:
#region Custom Sql
#region BeforeDropPrimaryKey
private const string BeforeDropPrimaryKeyMigrationBegin = @"DROP PROCEDURE IF EXISTS `POMELO_BEFORE_DROP_PRIMARY_KEY`;
CREATE PROCEDURE `POMELO_BEFORE_DROP_PRIMARY_KEY`(IN `SCHEMA_NAME_ARGUMENT` VARCHAR(255), IN `TABLE_NAME_ARGUMENT` VARCHAR(255))
BEGIN
DECLARE HAS_AUTO_INCREMENT_ID TINYINT(1);
DECLARE PRIMARY_KEY_COLUMN_NAME VARCHAR(255);
DECLARE PRIMARY_KEY_TYPE VARCHAR(255);
DECLARE SQL_EXP VARCHAR(1000);
SELECT COUNT(*)
INTO HAS_AUTO_INCREMENT_ID
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `Extra` = 'auto_increment'
AND `COLUMN_KEY` = 'PRI'
LIMIT 1;
IF HAS_AUTO_INCREMENT_ID THEN
SELECT `COLUMN_TYPE`
INTO PRIMARY_KEY_TYPE
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `COLUMN_KEY` = 'PRI'
LIMIT 1;
SELECT `COLUMN_NAME`
INTO PRIMARY_KEY_COLUMN_NAME
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `COLUMN_KEY` = 'PRI'
LIMIT 1;
SET SQL_EXP = CONCAT('ALTER TABLE `', (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA())), '`.`', TABLE_NAME_ARGUMENT, '` MODIFY COLUMN `', PRIMARY_KEY_COLUMN_NAME, '` ', PRIMARY_KEY_TYPE, ' NOT NULL;');
SET @SQL_EXP = SQL_EXP;
PREPARE SQL_EXP_EXECUTE FROM @SQL_EXP;
EXECUTE SQL_EXP_EXECUTE;
DEALLOCATE PREPARE SQL_EXP_EXECUTE;
END IF;
END;";
private const string BeforeDropPrimaryKeyMigrationEnd = @"DROP PROCEDURE `POMELO_BEFORE_DROP_PRIMARY_KEY`;";
#endregion BeforeDropPrimaryKey
#region AfterAddPrimaryKey
private const string AfterAddPrimaryKeyMigrationBegin = @"DROP PROCEDURE IF EXISTS `POMELO_AFTER_ADD_PRIMARY_KEY`;
CREATE PROCEDURE `POMELO_AFTER_ADD_PRIMARY_KEY`(IN `SCHEMA_NAME_ARGUMENT` VARCHAR(255), IN `TABLE_NAME_ARGUMENT` VARCHAR(255), IN `COLUMN_NAME_ARGUMENT` VARCHAR(255))
BEGIN
DECLARE HAS_AUTO_INCREMENT_ID INT(11);
DECLARE PRIMARY_KEY_COLUMN_NAME VARCHAR(255);
DECLARE PRIMARY_KEY_TYPE VARCHAR(255);
DECLARE SQL_EXP VARCHAR(1000);
SELECT COUNT(*)
INTO HAS_AUTO_INCREMENT_ID
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `COLUMN_NAME` = COLUMN_NAME_ARGUMENT
AND `COLUMN_TYPE` LIKE '%int%'
AND `COLUMN_KEY` = 'PRI';
IF HAS_AUTO_INCREMENT_ID THEN
SELECT `COLUMN_TYPE`
INTO PRIMARY_KEY_TYPE
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `COLUMN_NAME` = COLUMN_NAME_ARGUMENT
AND `COLUMN_TYPE` LIKE '%int%'
AND `COLUMN_KEY` = 'PRI';
SELECT `COLUMN_NAME`
INTO PRIMARY_KEY_COLUMN_NAME
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA()))
AND `TABLE_NAME` = TABLE_NAME_ARGUMENT
AND `COLUMN_NAME` = COLUMN_NAME_ARGUMENT
AND `COLUMN_TYPE` LIKE '%int%'
AND `COLUMN_KEY` = 'PRI';
SET SQL_EXP = CONCAT('ALTER TABLE `', (SELECT IFNULL(SCHEMA_NAME_ARGUMENT, SCHEMA())), '`.`', TABLE_NAME_ARGUMENT, '` MODIFY COLUMN `', PRIMARY_KEY_COLUMN_NAME, '` ', PRIMARY_KEY_TYPE, ' NOT NULL AUTO_INCREMENT;');
SET @SQL_EXP = SQL_EXP;
PREPARE SQL_EXP_EXECUTE FROM @SQL_EXP;
EXECUTE SQL_EXP_EXECUTE;
DEALLOCATE PREPARE SQL_EXP_EXECUTE;
END IF;
END;";
private const string AfterAddPrimaryKeyMigrationEnd = @"DROP PROCEDURE `POMELO_AFTER_ADD_PRIMARY_KEY`;";
#endregion AfterAddPrimaryKey
#endregion
我想大部分童鞋使用MySQL时,基本没迁移过,在实际迁移时会可能会抛出如下异常
Incorrect table definition; there can be only one auto column and it must be defined as a key
此问题一直遗留至今并未得到很好的解决,根本问题在于主键唯一约束问题,所以我们在得到脚本文本后,进行如下操作变换即可
var migrationsSqlGenerator = context.GetService<IMigrationsSqlGenerator>();
var commandList = migrationsSqlGenerator.Generate(migrationOperations);
if (!commandList.Any())
{
return;
}
var sqlScript = string.Concat(commandList.Select(c => c.CommandText));
if (string.IsNullOrEmpty(sqlScript))
{
return;
}
var builder = new StringBuilder();
builder.AppendJoin(string.Empty, GetMigrationCommandTexts(migrationOperations, true));
builder.Append(sqlScript);
builder.AppendJoin(string.Empty, GetMigrationCommandTexts(migrationOperations, false));
var sql = builder.ToString();
sql = sql.Replace("AUTO_INCREMENT", "AUTO_INCREMENT UNIQUE");
PostgreSQL脚本生成差异
要操作PG数据库,我们基本都使用Npgsql来进行,在查询获取数据库模型时基本也会抛出如下异常
Cannot parse collation name from annotation: pg_catalog.C.UTF-8
PG数据库基于架构(schema)和排序规则(collation),但在Npgsql中还不能很好支持,比如PG数据库存在如下架构和排序规则
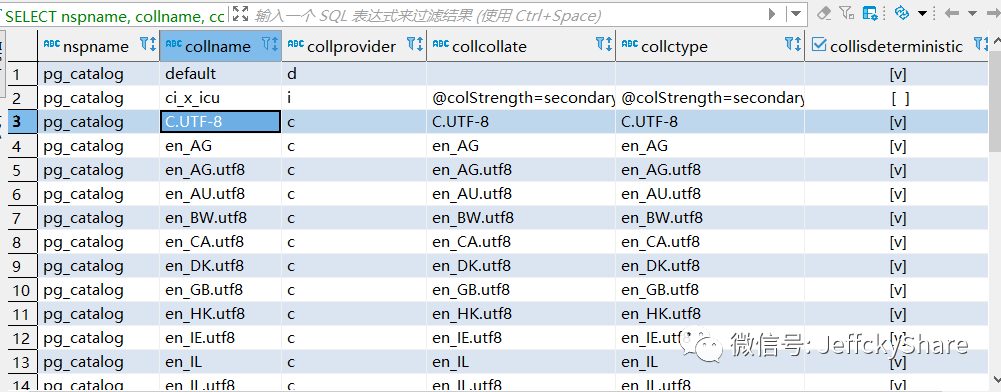
直到Npgsql EF Core 7预览版该问题仍未得到解决,作为遗留问题一直存在,当由第一列(schema)和第二列(collation)查询以点组合,在校验时以点分隔,数组长度超过3位,必定抛出异常,所以目前排序规则仅支持default和ci_x_icu,源码如下:
// TODO: This would be a safer operation if we stored schema and name in the annotation value (see Sequence.cs).
// Yes, this doesn't support dots in the schema/collation name, let somebody complain first.
var schemaAndName = annotation.Name.Substring(KdbndpAnnotationNames.CollationDefinitionPrefix.Length).Split('.');
switch (schemaAndName.Length)
{
case 1:
return (null, schemaAndName[0], elements[0], elements[1], elements[2], isDeterministic);
case 2:
return (schemaAndName[0], schemaAndName[1], elements[0], elements[1], elements[2], isDeterministic);
default:
throw new ArgumentException($"Cannot parse collation name from annotation: {annotation.Name}");
}
其他细节考虑
我们知道不同数据库肯定各有差异,差异性主要体现在两点上
其一有大小写区分,比如SQL Server并不区分,而MySQL虽区分但可以在配置文件中设置,人大金仓也好,高斯数据库也好,底层都是基于PG,所以都区分大小写,同时二者在部署时就需明确是否区分大小写,而且对于日期类型还存在时区问题
其二,不同数据库列类型不一样,比如SQLite仅有INTEGER和TEXT等类型,而SQL Server有NVARCHAR和VARCHAR,但PG数据库仅有VARCHAR,若我们对模型列类型以及长度等等不能有统一规范,那么完全通过代码迁移势必会带来一个问题,那就是每次都可能会得出迁移差异。比如我们使用SQL Server数据库,模型如下:
[Table("test1")]
public class Test
{
[Column("id")]
public int Id { get; set; }
[Column("name")]
public string Name { get; set; }
}
我们对属性Name类型和长度并未做任何处理,若我们在实际开发过程中,在数据库中将该列类型修改为VARCHAR(30),我们知道EF Core通过命令迁移生成数据库模型时,该列将使用默认约定即映射为NVARCHAR(MAX),通过代码生成的迁移脚本文本则为如下
DECLARE @var0 sysname;
SELECT @var0 = [d].[name]
FROM [sys].[default_constraints] [d]
INNER JOIN [sys].[columns] [c] ON [d].[parent_column_id] = [c].[column_id] AND [d].[parent_object_id] = [c].[object_id]
WHERE ([d].[parent_object_id] = OBJECT_ID(N'[test1]') AND [c].[name] = N'name');
IF @var0 IS NOT NULL EXEC(N'ALTER TABLE [test1] DROP CONSTRAINT [' + @var0 + '];');
ALTER TABLE [test1] ALTER COLUMN [name] nvarchar(max) NULL;
DECLARE @var1 sysname;
SELECT @var1 = [d].[name]
FROM [sys].[default_constraints] [d]
INNER JOIN [sys].[columns] [c] ON [d].[parent_column_id] = [c].[column_id] AND [d].[parent_object_id] = [c].[object_id]
WHERE ([d].[parent_object_id] = OBJECT_ID(N'[test1]') AND [c].[name] = N'id');
IF @var1 IS NOT NULL EXEC(N'ALTER TABLE [test1] DROP CONSTRAINT [' + @var1 + '];');
ALTER TABLE [test1] ALTER COLUMN [id] int NOT NULL;
所以基于完全通过代码而非命令迁移,前提应该是针对不同数据库定义属于对应数据库支持的列类型格式,如此这般才能避免每次都可能会生成差异性迁移脚本文本从而执行,比如字符串类型可能为中文,此时对于SQL Server就定义为NVARCHAR或其他,而SQLite为TEXT,PG数据库则是VARCHAR或其他,最后再来一下
if (context.Database.IsSqlite())
{
ioTMigrationFactory = new IoTSqlliteMigrationFactory();
}
else if (context.Database.IsSqlServer())
{
ioTMigrationFactory = new IoTSqlServerMigrationFactory();
}
else if (context.Database.IsMySql())
{
ioTMigrationFactory = new IoTMySqlMigrationFactory();
}
else if (context.Database.IsNpgsql())
{
ioTMigrationFactory = new IoTPostgreSQLMigrationFactory();
}
else if (context.Database.IsKdbndp())
{
ioTMigrationFactory = new IoTKdbndpMigrationFactory();
}
if (ioTMigrationFactory == default(IIoTMigrationFactory))
{
return;
}本文我们重点介绍如何生成脚本文本以及对于不同数据库需要进行对应逻辑处理存在的差异性,以及想完全通过代码而非命令执行迁移所需要遵循对于不同数据库配置不同列类型规范,避免每次都会进行差异性脚本执行,尤其是涉及开发人员手动更改列类型,带来脚文本执行自动覆盖的问题,
