个人认为爬虫框架分为抓取框架和分析框架
1)抓取框架
.net 市面上好的似乎不多,选择要素分两种:1.轻量型,2.重量型。
1. 轻量型是可以定制一些特殊的功能或者插件开关形式。总体性能高,速度快。
自己写的webclient,httprequest,httpclient等。或者直接socket编写!
2. 重量型是可以基本模式浏览器,更加傻瓜化,也基本屏蔽了一些反爬虫机制。
如webbrower或者其他的webkit浏览器内核封装的.net框架。
抓取的特殊功能包括:cookie支持(默认),301自动跳转,https默认支持,gzip等压缩默认支持,自动多种方式识别编码,默认模拟浏览器header,模拟css和js执行等等。
当然越是功能强大,性能越差些,但是适应各种情况的能力越强(反爬虫能力),轻量型和重量型适应的抓取场景也都不一样。
技术选择:
HttpHelper(作者是收费的,看了源码,其实功能也不强大;自己也能做,只是原来写的http框架源码没了,急着用暂时用下)
scrapysharp 中的ScrapingBrowser
.net HttpWebRequest 简单封装下
.net webclient 简单封装下
2)分析框架
旧技术:正则表达式
新方式: scrapysharp,HtmlAgilityPack,CsQuery 等等(还有很多)
scrapysharp:扩展自HtmlAgilityPack,非常好用。(支持css选择器方式,快速上手)
http://www.cnblogs.com/arxive/p/7075306.html

HtmlAgilityPack:本来就好用,但是用的时候还是要进行部分算法处理。(支持xpath方式获取,快速上手)
百度一下,资料不少。
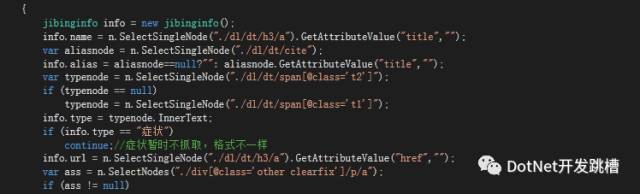
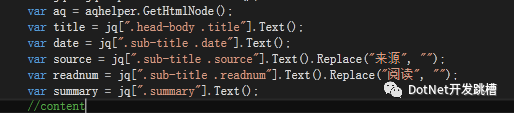
CsQuery:似乎对中文 的支持有bug,获取html的时候,中文会乱码,不知道为什么。(支持jq方式获取,快速上手)
https://github.com/jamietre/CsQuery
开源是一种态度,分享是一种精神,学习仍需坚持,进步仍需努力,.net生态圈因你我更加美好。
