前两天在微信后台收到了读者的私信,问了一个这样的问题,由于私信回复有字数和篇幅限制,我在这里统一回复一下。读者的问题是这样的:
大佬您好,之前读了您的文章受益匪浅,我们有一个项目经常占用 7-8GB 的内存,使用了您推荐的
ArrayPool以后降低到 4GB 左右,我还想着能不能继续优化,于是 dump 看了一下,发现是ArrayPool对应的一个数组有几万个对象,这个类有 100 多个属性。我想问有没有方法能复用这些对象?感谢!
根据读者的问题,我们摘抄出重点,现在他的数组已经得到池化,但是数组里面存的对象很大,从而导致内存很大。.
我觉得一个类有 100 多个属性应该是不太正常的,当然也可能是报表导出之类的需求,如果是普通类有 100 多个属性,那应该做一些抽象和拆分了。
如果是少部分的大对象需要重用,那其实可以使用ObjectPool,如果是数万个对象要重用,那么ObjectPool里面的 CAS 算法会成为瓶颈,那有没有更好的方式呢?其实解决方案就在ArrayPool类本身,可能大家平时没有注意过。
再聊 ArrayPool
我们再来回顾一下ArrayPool的用法,它的用法很简单,核心就是Rent和Return两个方法,演示代码如下所示:
using System.Buffers;
namespace BenchmarkPooledList;
public class ArrayPoolDemo
{
public void Demo()
{
// get array from pool
var pool = ArrayPool<byte>.Shared.Rent(10);
try
{
// do something
}
finally
{
// return
ArrayPool<byte>.Shared.Return(pool);
}
}
}
其实对于上面的这个问题,ArrayPool已经有了解决方案,不知道大家有没有注意Return方法有一个默认参数clearArray=false.
public abstract void Return (T[] array, bool clearArray = false);
其中clearArray的含义就是当数组被归还到池时,是不是清空数组,也就是会不会将数组的所有元素重置为null,看下面的例子就明白了。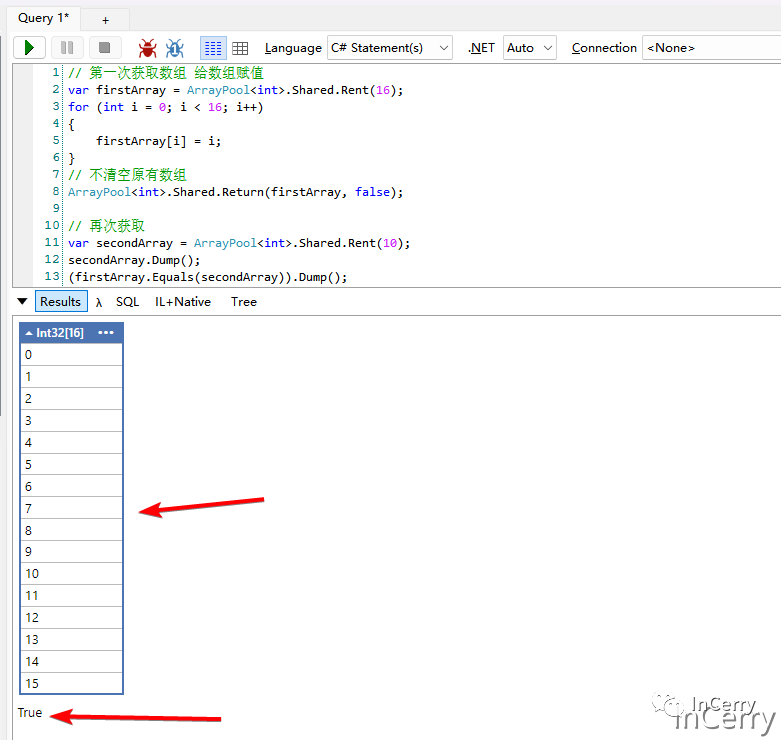
可以发现只要在归还到数组时不清空,那么第二次拿到的数组还是会保留值,基于这样一个设计,我们就可以在复用数组的同时复用对应的元素对象。
性能比较
那么这样是否能解决之前提到的问题呢?我们很简单就可以构建一个测试用例,一个在代码里面使用new每次创建对象,另外一个尽量复用对象,为null时才创建。
// 定义一个大对象,放了40个属性
public class BigObject
{
public string P1 { get; set; }
public string P2 { get; set; }
public string P3 { get; set; }
.....
}
然后创建一个数据集,生成1000条数据,使用默认的方式,每次都new对象。
private static readonly string[] Datas = Enumerable.Range(0, 1000).Select(c => c.ToString()).ToArray();
[Benchmark(Baseline = true)]
public long UseArrayPool()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
pool[i] = new BigObject
{
P1 = Datas[i],
P2 = Datas[i],
P3 = Datas[i]
// .... 省略赋值代码
};
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool);
}
}
另外一种方式就是复用对象池的对象,只有为null时才创建:
[Benchmark]
public long UseArrayPoolNeverClear()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
// 复用obj 为null时才创建
var obj = pool[i] ?? (pool[i] = new BigObject());
obj.P1 = Datas[i];
obj.P2 = Datas[i];
obj.P3 = Datas[i];
// .... 省略赋值代码
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool, false);
}
}
可以看一下 Benchmark 的结果: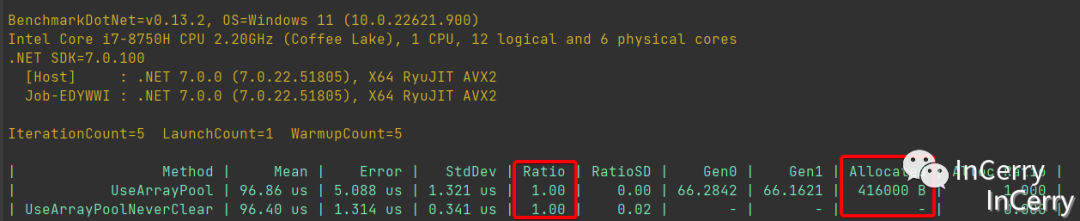
复用大对象的场景下,在没有造成性能的下降的情况下,内存分配几乎为0。
ArrayObjectPool
之前笔者实现了一个类,优化了一下上面代码的性能,但是之前换了电脑,没有备份一些杂乱数据,现在找不到了。
具体优化原理是每一次都要进行null比较还是比较麻烦,而且如果能确定其数组不变的话,这些 null 判断是可以移除的。
凭借记忆写了一个 Demo,主要是确立在池里的数组是私有的,初始化一次以后就不需要再初始化,所以只要检测第一个元素是否为null就行,实现如下所示:
// 应该要实现IList<T>接口 和 ICollection<T> 等等的接口
// 不过这只是简单的demo 各位可以自行实现
public class ArrayObjectPool<T> : IDisposable // , IList<T>
where T : new()
{
// 创建一个独享的池
private static ArrayPool<T> _pool = ArrayPool<T>.Create();
private readonly T[] _items;
public ArrayObjectPool(int size)
{
Length = size;
_items = _pool.Rent(size);
if (_items[0] is not null) return;
// 如果第一个元素为null 说明是没初始化的
// 那么需要初始化
for (int i = 0; i < _items.Length; i++)
{
_items[i] = new T();
}
}
// 为了安全只实现get
public T this[int index]
{
get
{
if (index < 0 || index > Length)
throw new ArgumentOutOfRangeException(nameof(index));
return _items[index];
}
set => throw new NotSupportedException();
}
public int Length { get; }
// 释放时返回数据
public void Dispose()
{
_pool.Return(_items);
}
/// <summary>
/// 当ArrayPool过大时 可以重新创建
/// 旧的池就会被GC 回收
/// </summary>
public static void Flush()
{
_pool = ArrayPool<T>.Create();
}
}
同样的,对比了一下性能,因为会创建一个对象,所以内存占用比直接使用ArrayPool要高几十个字节,但是由于不用比较null,是实现里面最快的(当然也快不了多少,就 2%):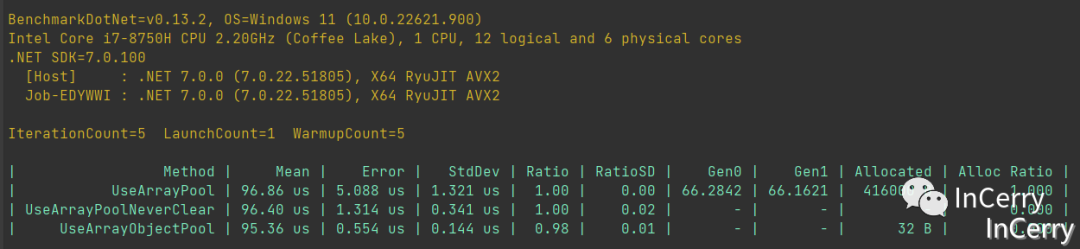
总结
我相信这个应该已经能回答提出的问题,我们可以在复用数组的时候复用数组所对应的对象,当然你必须确保复用对象没有副作用,比如复用了旧的脏数据。
如果不是经常写这样的代码,像笔者一样封装一个ArrayObjectPool也没有必要,笔者本人也就写过那么一次,如果经常有这样的场景,那可以封装一个安全的ArrayObjectPool,想必也不是什么困难的事情。
感谢阅读,如果您有什么关于性能优化的疑问,欢迎在公众号留言。
