最近查MSDN时发现有建议开发者使用Dictionary代替Hashtable的描述,出于好奇测试了Hashtable及Dictionary读写性能,发现无论读还是写Dictionary都大幅领先Hashtable,然后就花时间整理了Dictionary操作逻辑试图找到这种性能提升的原因(最后会发现实现上的差异带来的性能明显提升也算的上是理所当然)。
下文实际是介绍的Dictionary的实现(调试中使用的源是corefx 3.1),其中穿插着对比了Hashtable的实现逻辑。.
二、Dictionary成员介绍
先简单介绍下 Dictionary里的主要成员(https://source.dot.net/#System.Private.CoreLib/Dictionary.cs)
如果你之前很少有关注过DIctionary或类似集合的实现,下面对成员的解释可能看起来会有些跳跃,不过您还是可以通过查看这些成员介绍形成一个大概的印象,后面一章节的内容会较详细的向您介绍Dictionary的操作细节会反复涉及到这些关键成员。
下文将讲述的Dictionary集合的实现都是基于DotNet平台的,不过主流托管平台/语言对于BLC基础库的实现都有很多相似的地方,即使您不使用DotNet平台也可以看一下,文中会极少的直接粘贴BLC源代码。
2.1、主要成员
private int[]? _buckets;
槽列表(HashTable也是靠槽位的概念来快速找到元素的,不过不会有个专门的单独列表)
private Entry[]? _entries;
实体列表
private int _count;
被填充的实体数量(不算被删除的数量,所以Count属性的值实际是 _count - _freeCount )
private int _freeList;
空实体索引(默认-1表示没有,如果有在TryInsert的时候就会往这个索引地址填充)
private int _freeCount;
空实体数量(指定entry被填充,然后又被清除就出现一个空实体,后面还没有被填充的实体不计入此数量)
private int _version;
版本(实体发生实质改动时++,用于遍历时确认列表有没有发生变化,如果有变化抛异常)
private IEqualityComparer? _comparer;
Key比较器
private KeyCollection? _keys;
Key列表(数据源自_entries)
private ValueCollection? _values;
Value列表(数据源自_entries)
private const int StartOfFreeList = -3;
计算free entry 的next 值的一个固定常量(next 默认0)
2.2、_buckets
_buckets 上面已经提到,因为他是一个较重要的成员这里再单独列出来进一步说明。
_buckets 是一个int数组,结构比较简单,数组大小是当前Dictionary的实际容量大小,不是Count的值(这个很大可能并不是初始化时用户指定的大小)
_buckets数组里的每个元素实际上包含2个关键信息
-
index:这个索引很重要,通过 [ hashcode(key)%_buckets.len ] 确定指定key应该落到的索引位置(不用遍历key,通过轻量计算可以快速直接找到数据) -
value:value为int类型实际上也是一个索引,这个索引指向了_entries数组里的真正目标实体(_buckets并没有直接放数据内容,但HashTable里是直接把内容都放到bucket[]里的)
2.3、_entries
_entries是一个Entry结构的数组,Entry结构如下。
private struct Entry
{
public uint hashCode;
/// <summary>
/// 0-based index of next entry in chain: -1 means end of chain
/// also encodes whether this entry _itself_ is part of the free list by changing sign and subtracting 3,
/// so -2 means end of free list, -3 means index 0 but on free list, -4 means index 1 but on free list, etc.
/// </summary>
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}
_entries直接存放Dictionary数据实体,加上数组的索引,每个元素有5个关键信息(索引实际不属于Entry结构的内容,方便说明放在一起解释)
-
index:这个索引就是_buckets里value的对应的值,key算出hashcode后先找到指定的bucket,碰撞发送时通过其value定位到_entries指定实体 -
hashCode:key的hashcode ,这里的hashcode是uint(HashTable的hashCode是不用最高位的,他的最高位1表示发生碰撞,而Dictionary使用next标记碰撞,所以会保留hashcode所有位,hashcode默认0,被填充后写入当前key的hashcode,存储hashcode是为了对比方便,key的比较先比较code会快很多,code不一样key肯定不一样,code一样key才可能一样,在当前entry被remove时,hashcode不更新,因为没有必要更新,int为值类型,数据0与12345654321消耗都是一样的,而且这里也没有用0表示特殊含义) -
key:存储TKey -
value:存储TValue -
next:比hashcode多出来的一个数据,不仅标记碰撞还记录了碰撞数据的完整链路,同时也标记了空槽的完整链路。
next = -1 : 已经插入了数据,并且他所在的_bucket槽位之前没有发生过碰撞,如果在查找碰撞key链时,他就是最后一个值
next >= 0 : 当前数据与_entries中那个key发生碰撞,注意这里的next指向的索引是_entries自己的索引位置(hashcode(key)%_buckets.len 是一样的即表示碰撞,他们会使用__bucket的同一个位置) (0为默认初始值,_entries不使用next的值判断这个位置是否为 空闲位置,他仅通过count及_freeCount,_freeList可以快速精确定位下一个合理的空闲地址)
next < -1 : 标记下一个空实体索引 (_freeList = StartOfFreeList - entries[_freeList].next;)即 |next|-3 (-3指向0索引,-4指向1索引,-2则表示已经到达尾部没有下一个空实体了,后面的数据会根据count确认位置)
典型构造函数如下
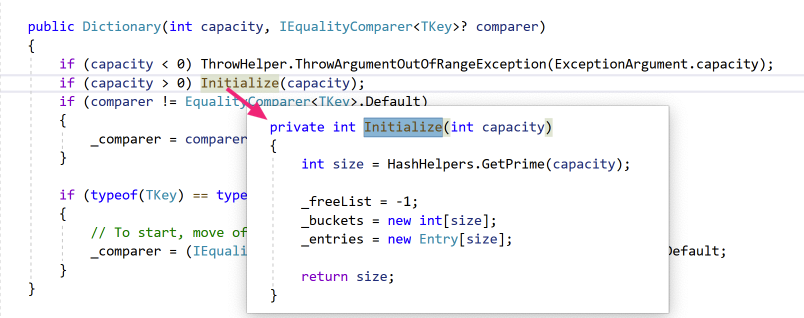
上面的代码逻辑我们可以看出较常用的参数为capacity(默认不填是取的0)。
通过Initialize函数,可以看到capacity这个值并不是这个Dictionary的真实容量,真正的大小是GetPrime(capacity) 即大于capacity的最近的一个素数,如果不填capacity那即是大于0的最近的一个素数,为3。
这里capacity是用户设置的容量,size是这个Dictionary真正的大小,count为当前Dictionary存储了多少个真正的数据
比如使用Dictionary(2)初始化时 capacity=2;size=3;count=0.
_freeList在构造函数中被初始化为-1 (隐含的_freeCount初始化为0 ,因为int默认就是0所以这里不用写)
_buckets及_entries在Dictionary初始化的时候也完成了初始化,数组大小已经被确定(值类型的数据资源已经全部被直接分配了)。
2.4、官方文档
下面是主要的2份官方文档
-
Dotnet Source Browser :https://source.dot.net/#System.Private.CoreLib/Dictionary.cs -
MSDN :https://docs.microsoft.com/zh-cn/dotnet/api/system.collections.generic.dictionary-2?redirectedfrom=MSDN&view=net-5.0
三、Dictionary 运作过程介绍
本章节重点通过分析Dictionary 添加,删除,查找等操作执行过程,让您理解Dictionary操作逻辑,花时间去推敲一下的话,一定会有不一样的体会,每一个操作都有其存在的意义,个人认为设计也可以说是相当精妙。
Dictionary 中维护数据主要靠2个数组buckets及entries,前面已经提到过buckets负责记录槽位信息,entries存储键值对。
这里有几点会被考虑到
-
数据是以怎样的顺序存入的 -
如何高效查找数据(不通过遍历的方式) -
如何处理碰撞 -
移除数据产生的空闲位如何重复利用 -
如何扩容
要搞清楚上面的问题,主要就是理解Dictionary元素的添加(包括更新)及删除逻辑。
3.1、新增元素(TryInsert)
插入流程概要
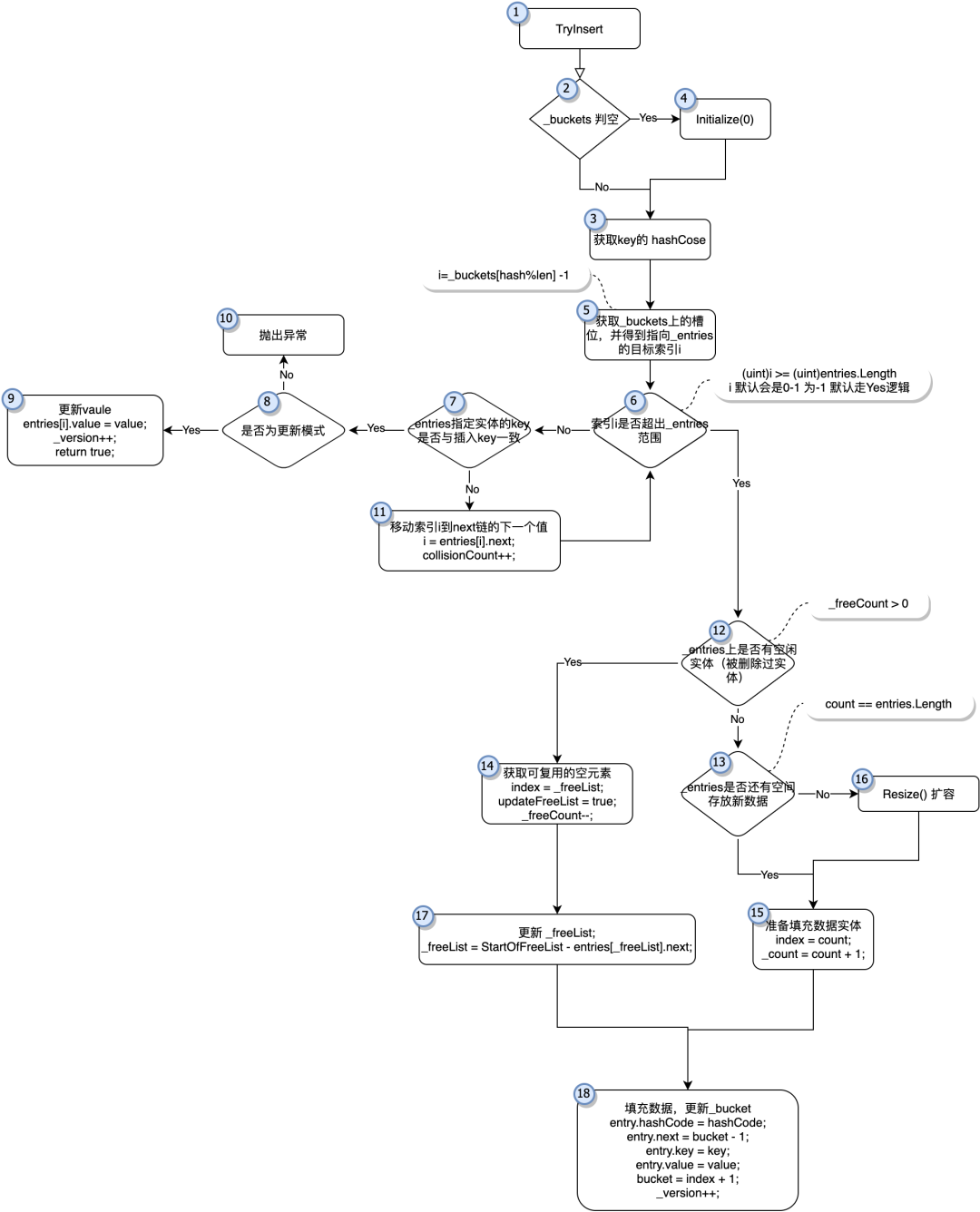
「图-TryInsert」
上图为新增元素的简单流程图(对应着TryInsert函数)
-
注意文中流程图是根据dotnet core 3.1 fx 的实际源代码省略了部分与元素存储关联不强的逻辑绘制出来的 。(不同版本coreFX 可能会略有不同) -
涉及到流程图虽然有简化部分逻辑,但是重要核心逻辑已多次核验,这里建议您可以对照Dotnet Source Browser里的源代码一起看。 -
因为官方源代码相关逻辑篇幅大且有许多关联性,如果只贴一部分很难描述全面,所以下文中会尽量避免直接贴代码,而是选择将源代码转换为流程图或图表进行介绍。
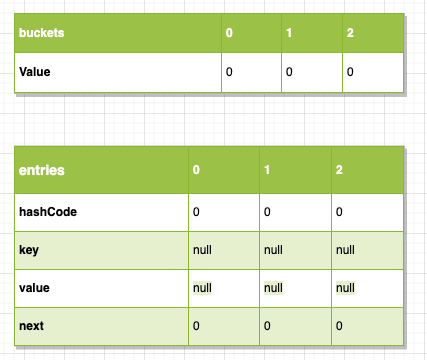
「图-entries-0」
上图以表格形式简单展示了dictionary内部的核心的buckets及entries数组结构。
dictionary插入元素的关键就是元素应该插入到entries数组的什么地方,如何在删改查时快速定位到元素。
分析插入如何执行
如图「图-TryInsert」为插入及更新的关键代码的简化流程图,在插入前有基本的参数校验,值得一提的是默认初始化函数Initialize(0)实际上将创建一个长度为3的存储空间如图「图-entries-0」
这里提一下Initialize(因为这个函数逻辑比较简单没有画流程图)
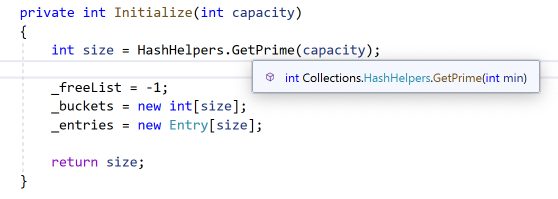
可以看到一个细节实际是dictionary的容量并不是我们指定的capacity,而是取的GetPrime的值
GetPrime(capacity) 实际是大于capacity的最小素数**因为这个数组的容量len会用在 hashcode%len 上计算元素应优先该落在哪个槽位,len使用素数会减少碰撞的发生从而提升读写效率(其实自己也没有搞明白为什么len使用素数求余就分布的更均匀,期待有了解的同学解答)
对TryInsert接下来就会计算Key的hashcode (所有类型的数据都有GetHashCode方法,它继承自Object,当然您可以为自己的数据类型重写该函数)
下面是很关键的一步计算该key对应的buckets槽位,这里直接使用hashCode % (uint)_buckets.Length 求余得到的索引即为buckets的索引号(不同版本的cocefx可能会有差异,这里调试使用的是dotnet core 3.1)。比如余的结果为y那buckets[y]对应的值即是entries的索引,即entries[buckets[y]]将是可能与key发生碰撞的数据实体,应该再此处检查碰撞(实际会更复杂一些,后面会讲到)
而buckets[y]的值应该是多少即决定着key要先在哪里进行碰撞(如果buckets[y]的值为0表示该key不会有碰撞)。碰撞完成插入数据时会在dictionary里在没有空位的情况下数据是会顺序插入到entries里的,即buckets[y]的值在这种情况下会更新为count的值,在有空位的情况下会优先插入到空位中(这与HashTable不同,因为HashTable内部只维持着一个数据数组,数据会直接存放在槽位上)
在Dictionary使用中您会发现,如果只插入数据不删除数据,那遍历的结果其实是有序的,它会与您插入时的顺序维持一致,不过MSDN上明确说明“返回项的顺序是不确定的”,因为在删除发生时,顺序就会变的不那么可控(不过本文将向您描述这种不确定的规则,您会发现它的顺序虽然不是完全按照插入的时序排列的,但它是有一个确定的规则的,最终您会发现您在某种程度上是可以完全控制他的顺序的)
现在请关注「图-TryInsert」的步骤5,步骤6。这里会描述buckets[y]的值是如何确认的
i=_buckets[hash%len] -1 (i即为后面entries的索引)
我们知道_buckets为一个init[],其中每个元素的默认初始值都会是0,所以bucket为0即表示初始状态(之前没有被任何key命中过)
此时如果在key没有发生碰撞,那i就是0-1=-1,-1这个索引因为越界是不能定位到_entries上的任意值的(corefx 使用 (uint)i >= (uint)entries.Length 判断i是否越界,一个负数的转换为uint是一定大于int的上限的)
这里_buckets[hash%len] -1 之所以还要-1,也是因为int默认值是0,而0也是一个正常的索引位置,为了让默认值不能表示任何数组索引需要-1
现在如果没有发生碰撞,会进入「图-TryInsert」的步骤12开始找合适的地方进行插入。(这个我们待会再看)
在这之前我们先来看下碰撞发生时Dictionary的处理机制,现在请关注「图-TryInsert」的步骤7,步骤11,他们是处理碰撞的关键。
检查到碰撞(如果_buckets[hash%len]是一个大于0的数字即表示有碰撞发生,与这个Key碰撞的数据就是entries[_buckets[hash%len] -1] )可能确实是遇到了一个重复的Key,所以需要在步骤7里进行检查,如果Key确实是重复的那很简单直接更新掉,如果现在是插入模式就抛出异常即可
注意更新时直接更新value即可,槽位信息_buckets及entry的hashcode,next值都是不用更新的,因为他们都没有发生改变,不过注意步骤7里_version此时会+1 ,这个_version用于遍历时数据版本的检查,后面会单独提到。
当然大部分情况可能是Key并不相同,确实有碰撞发生,这个时候需要通过entry的next去寻找下一个可能存在的碰撞地址。
如「图-TryInsert」步骤11中的描述发现这种碰撞后,会直接将entries的数据索引移动到entries[i].next (记录碰撞次数的collisionCount也会加1)
关于next的值,在数据被插入时会进行赋值entry.next = bucket - 1前面讲过bucket的默认值是0,那next的默认值就是0-1=-1而当有碰撞的情况下,bucket的值就是直接发生的那一个entry的索引+1,这种情况下next值就正好会是与当前entry发生碰撞的第一个entry的索引,entries也就是靠next维持着碰撞链路,一个hashcode可能会碰撞许多次,他们利用next形成一个链表,查询时只需要查询这个链表即可,如果链表查到底都没有发现重复的Key,那这个Key就是一个新的Key,直接插入即可。同时新插入的entry会成为前面碰撞链表的头一个数据。
然后会再次进入「图-TryInsert」步骤6,并循环6 > 7 > 11 > 6 ,直到entry.next为-1 (或者进入之前看过的步骤8)当碰撞完成后最终会进入插入流程。
现在我们回到「图-TryInsert」的步骤12,在这里dictionary会检查entries中是否存在空位(空位是由元素删除产生的,后面会单独分析删除的机制)。前面已经提到过_freeCount,他由Dictionary维护,很容易理解大于0就是有空位,我们先看没有空位的情况。
「图-TryInsert」的步骤13,15,18即是没有空位的路径,如果没有空位就会使用新位,那就有数组长度不足的情况,一旦entries空间被占满,那在下一次插入时即会发生扩容
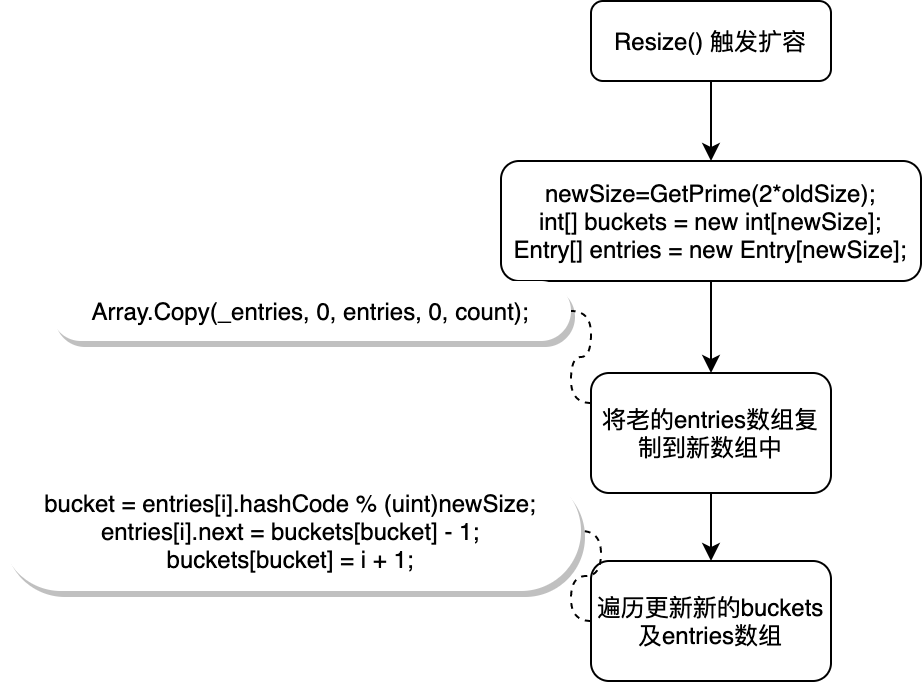
扩容的逻辑相对简单,新的大小为GetPrime(2*oldSize),需要注意的是老的entries被复制到新数组后由于len发生了变化_bucket及entries[i].next都需要重新计算并更新。hashcode用新的size求余得到bucket(这里的bucket代表的是buckets数组的一个索引),并将entries[i].next指向bucket之前指向的数据,再更新bucket的值为当前entry的索引,注意这里并没有像TryInsert一样去碰撞链中对比Key的实际值是否相等,因为扩容的数据都是老数据是不可能有重复Key的。
entries复制到新数组后,看起来next似乎是不用更新的,因为这些元素的碰撞链看似不会变。但实际上并非如此,因为数组的长度变了,那每个元素的hashcode%len的值会发生变化,这个碰撞链也会随之发生变化
dictionary扩容是发生在entries被耗尽的下一次插入时,而HashTable的扩容是发生在count>hashsize*loadFactor时,负载因子默认0.72。因为HashTable没有单独的_buckets维护槽位信息,在元素数量接近hashsize时由插入位已被使用而导致碰撞概率将显著提高,所以需要提前扩容。
前面也有提到过对于没有空位的entries来说插入是顺序插入的,所以这个时候确认插入新数据的位置index=count,同时_count的值加1。
在正式填充插入数据前,我们先看下步骤12的另外一个路径,entries上有空位的情况 「图-TryInsert」的步骤14,17
一旦发现空位dictionary会先使用空位,index会被设置为最后一个空位的索引值即_freeList,同时_freeCount--
因为空位很可能不止一个,我们现在把_freeList这个空位使用掉了,那就需要把_freeList指向下一个空位StartOfFreeList - entries[_freeList].next ,空位同样使用next维持着一个空位链表,我们使用完第一个,把下给_freeList就可以(这个空位链表是如何运作的我们会在下面的Remove中单独说明)
这里还有一个细节,在使用空位时,_count其实并没有+1,实际上_count只是标记着_entries被使用到的位置,并不是整个dictionary的大小,dictionary的Count属性是通过_count - _freeCount 计算得出来的。
现在回到「图-TryInsert」的最后一步 步骤18,因为已经确认index了,现在只需要把数据填充到_entries[index]里就可以了
-
entry.hashCode = hashCode; //更新hashCode -
entry.next = bucket - 1; //更新next 如果没有碰撞初始buctet是0,next就会是-1,否则next会是碰撞链的下一个索引 -
entry.key = key; //填充key -
entry.value = value; //填充value -
bucket = index + 1; //更新bucket的新值指向当前entry,下次再有hashcode命中这个bucket就会先找到当前entry开始碰撞流程 -
_version++; //更新数据版本,遍历时需要确保版本一致
3.2、删除元素(Remove)
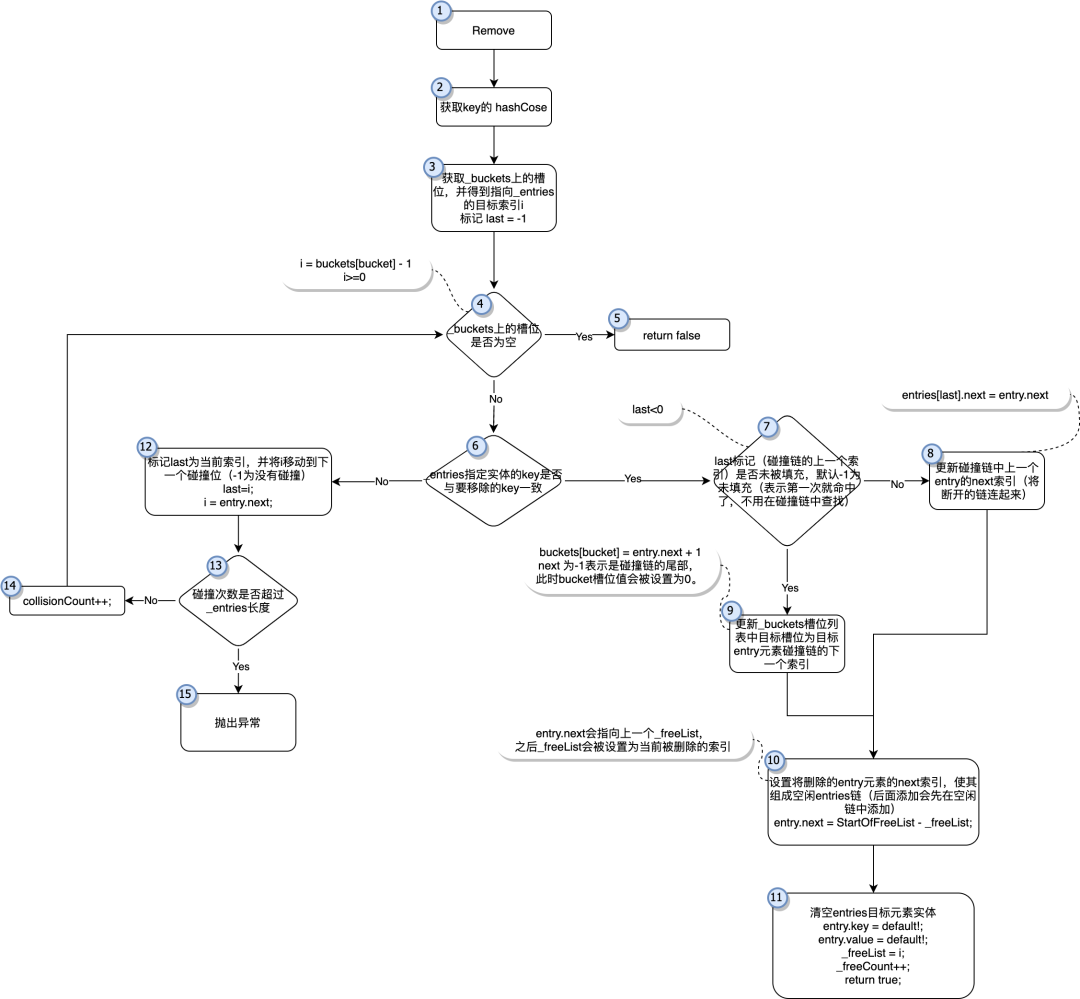
上图为移除元素的简单流程图(对应着Remove函数)
在前面的添加中我们已经提到插入数据时如果遇到空位是要先插入空位的,而空位就是在Remove中产生的,同时他还负责维护空位链表。
如「图-Remove」步骤1,2,3 与TryInsert是类似的,都是先获取到hashcode。不过在步骤4中稍有不同,通过hashcode定位到buckets上的槽位,如果槽位值没有指向entries里的任何元素(buckets[bucket] - 1>=0)就直接返回false,反之则继续
我们知道bucket默认值是0,一旦发生数据插入他的值会被改为entries的index+1。如果一个hashcode对应的bucket的值是0,那说明这个key不可能曾经被插入过,所以不用搜索也知道key在dictionary里肯定不存在,直接返回false就可以了。
现在我们来看步骤6(它与TryInsert的步骤7类似)这个时候已经通过bucket找到了位于_entries上的一个值,但是它很可能只是一次碰撞,所以我们需要直接对比Key确认这个元素是不是我们要找的元素,如果不是反复进行步骤6 > 12 > 13 > 14 > 4 > 6,直到到步骤4到达碰撞链结尾如果还是没有发现目标Key返回false结束函数,或者找到目标Key,进入删除流程。
现在来到步骤7,这是很关键的一步,因为目标Key如果存在碰撞链中,那它可能是碰撞链中的任意一个元素,如果在中间进行删除那就还需要修复断链。Remove使用一个last局部变量来标记上一个碰撞链中元素的索引(默认为-1,大于-1表示存在上一个空位,即表示会在链中进行删除),如果last为初始值-1就直接进入删除流程,如果不是则需要在删除前先修改碰撞链 entries[last].next = entry.next (如果被删除的Key正好是碰撞的尾部,那next将会是-1,同样这个尾部的标记会转给entries[last])。这2个流程在步骤8,步骤9中体现
前文TryInsert中还提到的一个空闲链也是在Remove里创建并维护的,在正式删除时需要将即将删除的元素变成空闲链的链首(后面如果会有插入地址将会优先使用)
*这里的空闲链也是通过next来维护的,我们知道next在entries中已经被用来维持碰撞链,不过entries对next的利用十分充分,它将同时用来维护空闲链。next=-1 代表当前元素有值且没有任何碰撞或位于碰撞链尾部next>=0 代表当前元素有值且处于碰撞链中,next的值就是下一个碰撞元素的索引**next=-2 代表当前元素已经被删除,且当前空位位于空闲链尾部(如果只有一个空闲,它同时也是首部)*next<-2 代表当前元素已经被删除, |next|-3 表示空闲链的下个(最后一个next一定是-2)
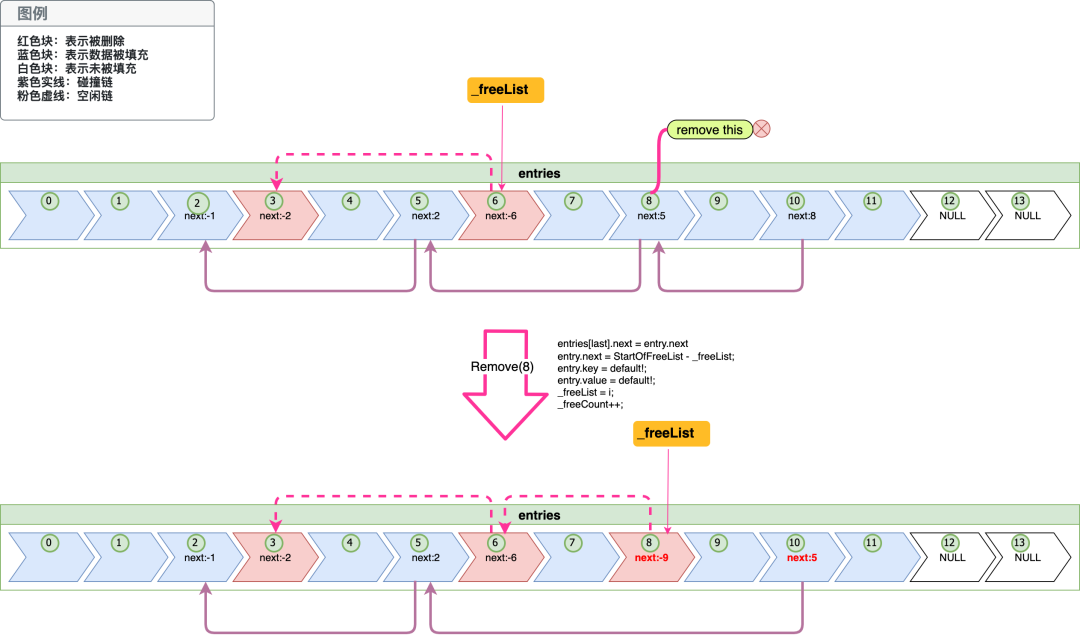
「图-删除元素」
上图简单的表述了一次删除中next在碰撞链及空闲链中的变化(上图省略了buckets的变化),上图entries上方的粉红虚线为空闲链,下方紫色实线为一条碰撞链(注意在entries中空闲链只会有一条,而碰撞链会有很多,上图只画了一条)。在「图-删除元素」我们称上面删除发生前的entries为状态1,下面删除后的为状态2。
现在我们先看状态1中的entries的空闲链,它的_freeList指向了entries[6],entries[6]就是空闲链的开始,然后-3-entries[6].next =3 就是空闲链的下一个索引为3即entries[6],这个时候我们发现entries[6].next已经是-2了,表示它已经是链尾了。
然后我们再来看下碰撞链,碰撞链从entries[10]开始,entries[10]的next是8,它就会链接到entries[8],以此类推一直找到链尾entries[2]
虽然我们现在要删除的是entries[8],不过我们通过key只能先找到entries[10],这是因为我们在插入entries[10]的时候,利用hashcode检查到碰撞将会将entries[10]放在碰撞链首
当删除发生时,key的hashcode会先引导我们找到entries[10],dictionary发现entries[10]不是目标元素,根据碰撞链找到entries[8],发现匹配成功,开始删除。这个时候我们可以看「图-删除元素」状态2中元素next值的变化(有变化的值已经用红色标记了),先看entries[10]它的next由8变成了5,因为entries[8]已经被删除了,现在这个链已经被链到了下一个即entries[5]身上。再来看下entries[8],它是被删除的元素其next由5变成了-9,删除前它是碰撞链的一环,删除后它就是空闲链的链首,next值指向空闲链的下一个(-3-(-9))即entries[6]。最后我们看下_freeList标记,它的指向也从entries[6]变成了entries[8](后面的插入就会先使用entries[8]的空间)。
「图-删除元素」中只是展示了元素删除的一种情况,删除的其他路径next的变化大家也可以通过前文中的介绍计算出来。
对于buckets数组来说,「图-删除元素」的这个流程下来其实他是不会发生变化的,因为要删除的元素不是位于碰撞链首,假设对于上图中的删除流程我们要删除的是entries[10](他是一条碰撞链的首部)那在删除完成后entries[10]对应的bucket的值就会变成entries[10].next-1。
不难发现对应dictionary来说是通过bucket的值,碰撞链来共同确认元素是不是被删除(存在),而对HashTable来说他主要通过使用其Key的值是不是null来确认(当然HashTable也需要借助自己的碰撞链完成确认)
3.3、元素的获取(FindEntry)
其实在我们看过dictionary中元素的新增及元素的删除后,获取元素就会相对简单很多(通过流程图也可以看出来FindEntry函数的流程相对少了很多)
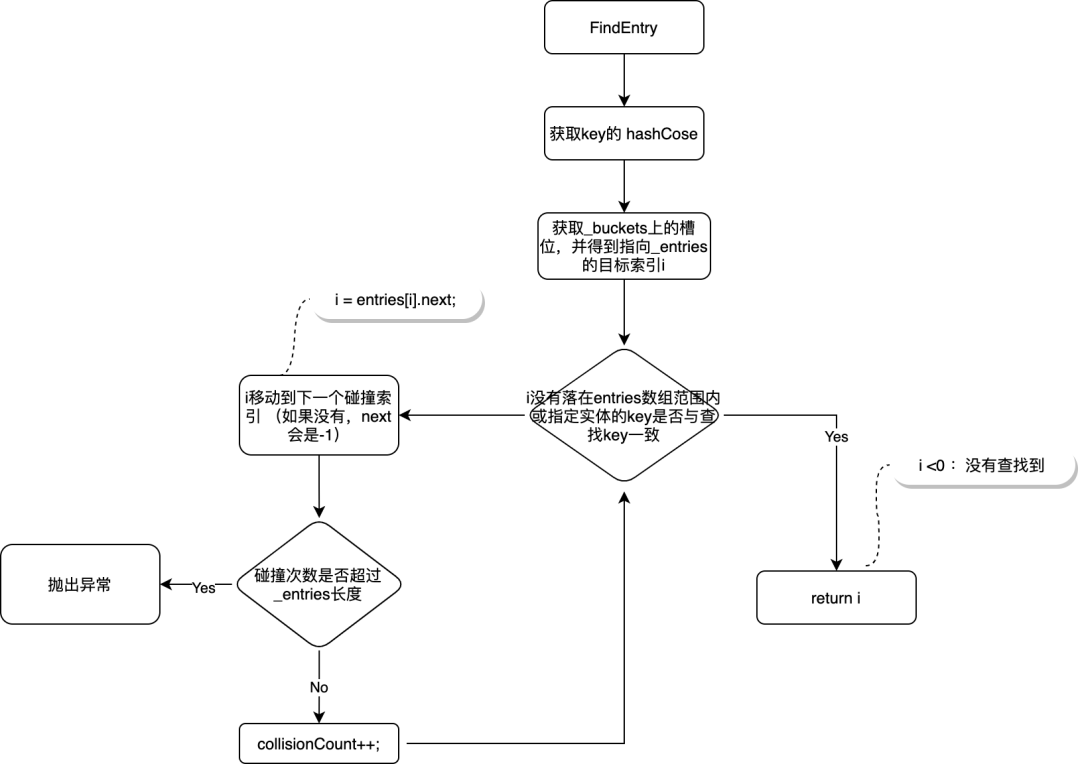
「图-FindEntry」
如上图是dictionary中通过key查找元素的关键代码的流程图,可以看到上面的流程几乎都在TryInsert及Remove中出现过,因为在新增及删除时其实都需要通过Key在dictionary里查找一遍有没有同样的Key,而查找逻辑是一致的,这里就不再重复讲述了。
四、解析一组操作的实际处理过程
4.1、实例介绍
通过上文我们已经知道dictionary是如何通过buckets与entries维护数据的,但无论如何2个数组之间的关系的确有些绕,要完全搞清楚里面的逻辑最好还是有实际的数据实例,接下来我们通过一个简单的例子来看下buckets,entries里的内容是如何变化的。(实例代码代码会触发新增,删除,扩容,碰撞及对空槽位的重复利用等关键步骤)
var dc = new Dictionary<string, string>(1);
dc.Add("1", "11");
dc.Add("2", "22");
dc.Add("3", "33");
dc.Add("4", "44");
dc.Remove("1");
dc.Remove("3");
dc.Add("1", "11");
dc.Add("5", "55");
代码如上,我们每运行一行,为buckets,entries里的数据做一次快照,分析其中的关系。
借助微软Soucrce Link,现在您不用自己编译corefx,就可以直接调试fx里基础库的源代码。下文图例中buckets,entries结构里的数据都是真实的数据(内存里就是这些确切的值),不是为了演示而创造的示例数据。
4.2、new Dictionary
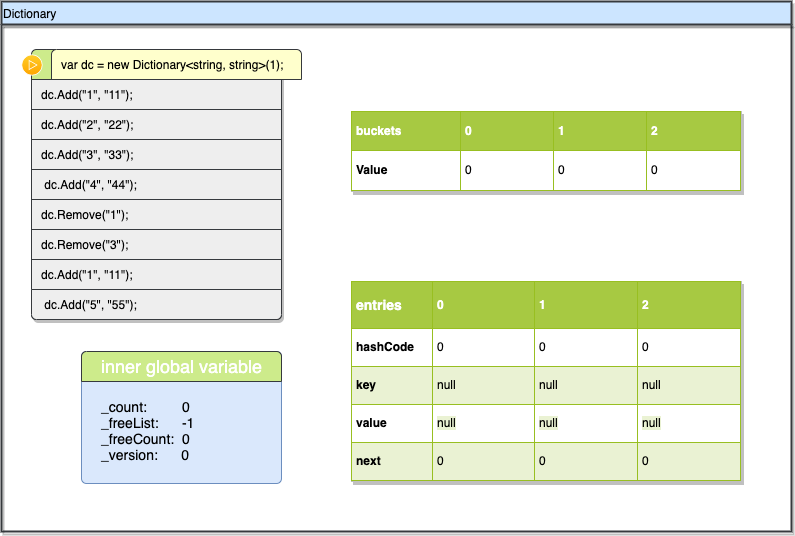
当运行new Dictionary<string, string="">(1)时,dc完成初始化,执行Initialize,上文已经提到过这个初始化函数它并不是用1来作为dc的容量,它使用大于1的第一个素数即3,所以执行初始化后dc的size会变成3,bucket与entries里的数据也都是初始值,int类型全部为0,引用类型为null。同时上图左下角记录了部分关键变量的值,注意_freeList为-1表示没有由于删除导致的空位,其余的都是默认值0
这里还有一点需要说明,我们在实际应用中我们一般不会指定Dictionary的大小,默认他会使用0去初始化,在这种情况下初始化时是不会去创建buckets及entries数组的,dictionary会在真实发生插入时再去创建这2个数组,创建出来的内容与上图的一致。
4.3、Add("1", "11")
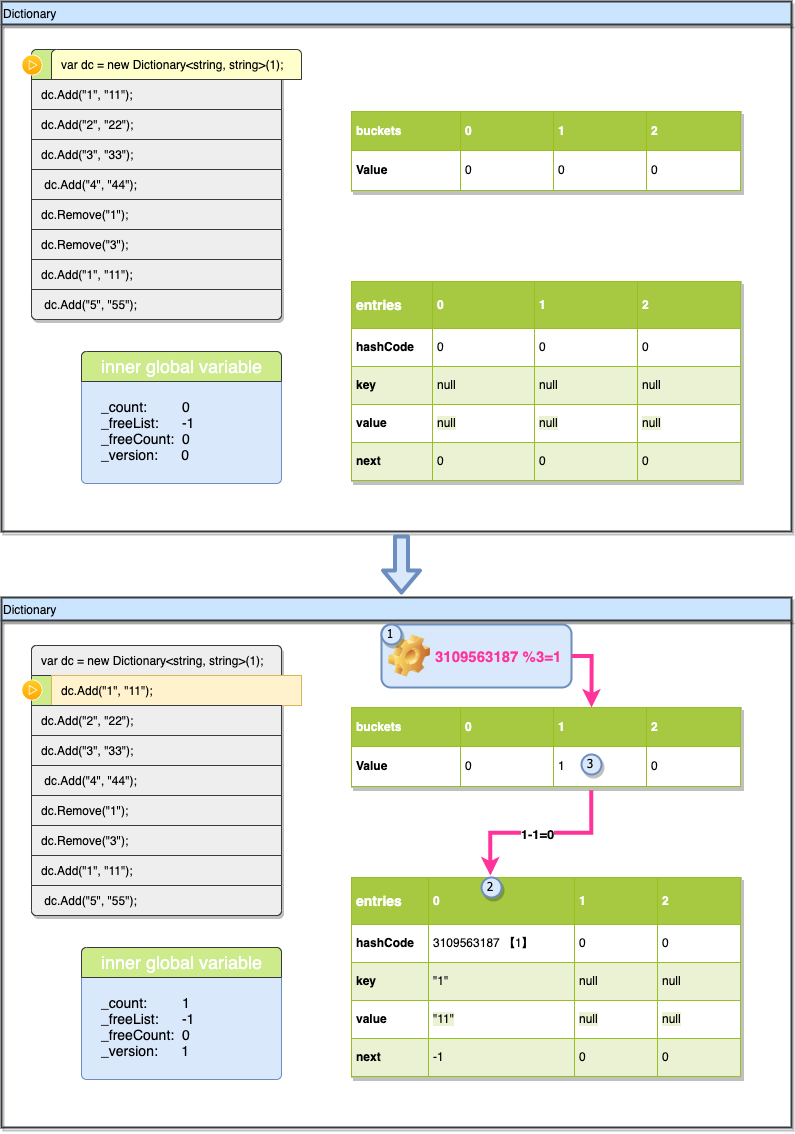
现在执行Add("1", "11"),我们计算“1”的hashcode为3109563187,然后我们通过3109563187%3的到索引1,表示他要使用buckets[1]这个槽位,这个槽位开始的值是0,表示之前没有元素使用过,可以直接插入。检查_freeList为-1,表示没有空位,开始按_count进行插入,初始_count为0,所以entries[0]就是要插入数据的位置,把hashcode,key,value插入进去,next取buckets[1]-1 为-1表示没有碰撞,最后更新buckets[1]的值为buckets[1]的索引+1即为1 ,插入完成后需要将_version++,_count也会+1。(上图中➀➁➂表示索引数据跟新的顺序,通过这个顺序可以看出一个细节buckets[1] 虽然一开始就要用到他,而他的值是最后才确定并写入的。后面的图例中将不再标注这个顺序,hashCode后的【1】表示hashcode%len的求余结果)
4.4、Add("2", "22")
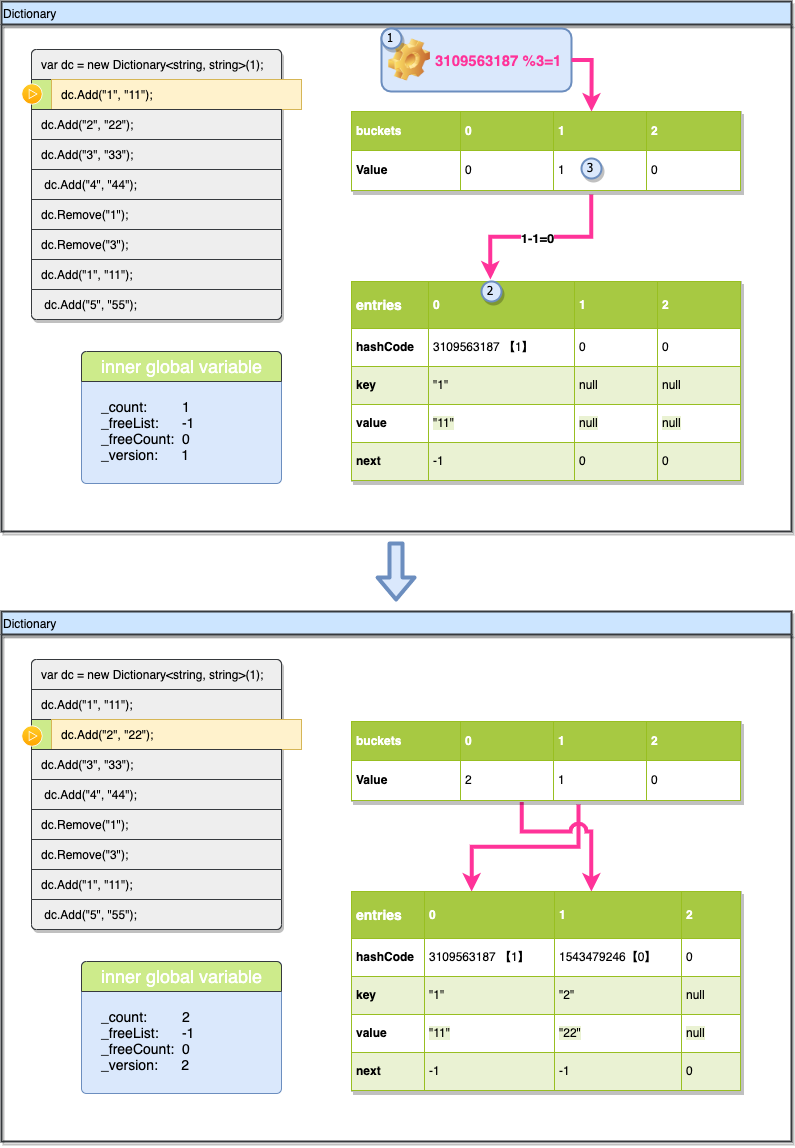
现在插入第2个Key,流程与上一个类似。这一次hashcode%len是0,所以对应的是第一个槽位,插入的位置也是以_count为索引,之前插入完成后_count已经+1,同样完成插入后_count与_version都递增1。
其实可以看出来在没有空位的情况下,插入就是按顺序一个接一个存放在entries数据数组里的,这与HashTable就有很大区别,HashTable实际只有一个buckets数组,数据及槽位信息都是放在一起的,HashTable的索引同时指向他们,所以HashTable数据不可能是以类似顺序的形式插入。
4.4、Add("3", "33")
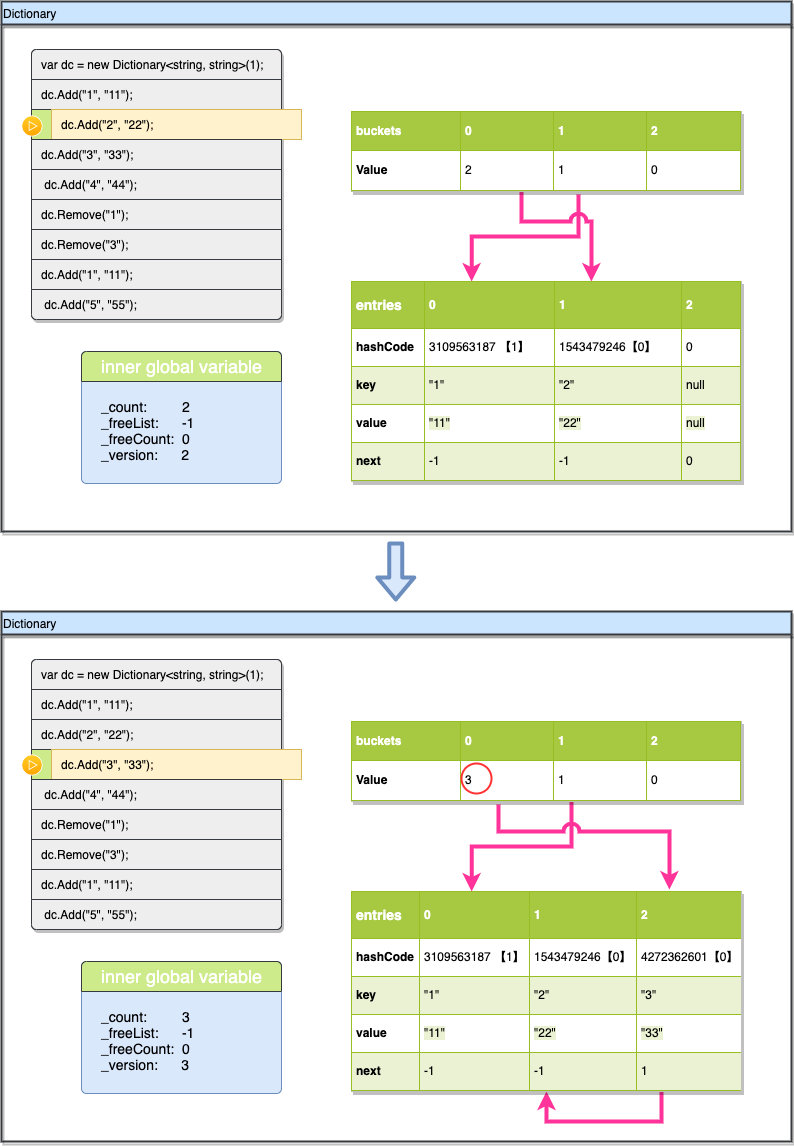
现在插入Key "3",这个时候稍微有些变化,因为插入时发生了碰撞,3的hashcode%3的值也是0(刚刚Key“2”也是0),所以我们先找到了buckets[0], buckets[0]-1=1 直接找到entries[1]对应的数据位(注意上图buckets[0]为3是指插入完成之后的值会更新为3,之前的值直接查看该图上部分快照数据即可),然后用entries[1].key与现在插入的key进行对比(避免插入重复key),然后检查entries[1].next 发现是-1(表示他后面没有碰撞链)那就直接在后面的空位entries[2]插入新数据就可以了(这里的“后面的空”是指下一个可用空间,并不是指数组的下一个),同时现在出现了一条碰撞链由entries[2]指向entries[1](右下方红线所示),不过现在buckets[0]的值需要更新,需要更新为entries[2]的索引+1即3。
4.6、Add("4", "44")
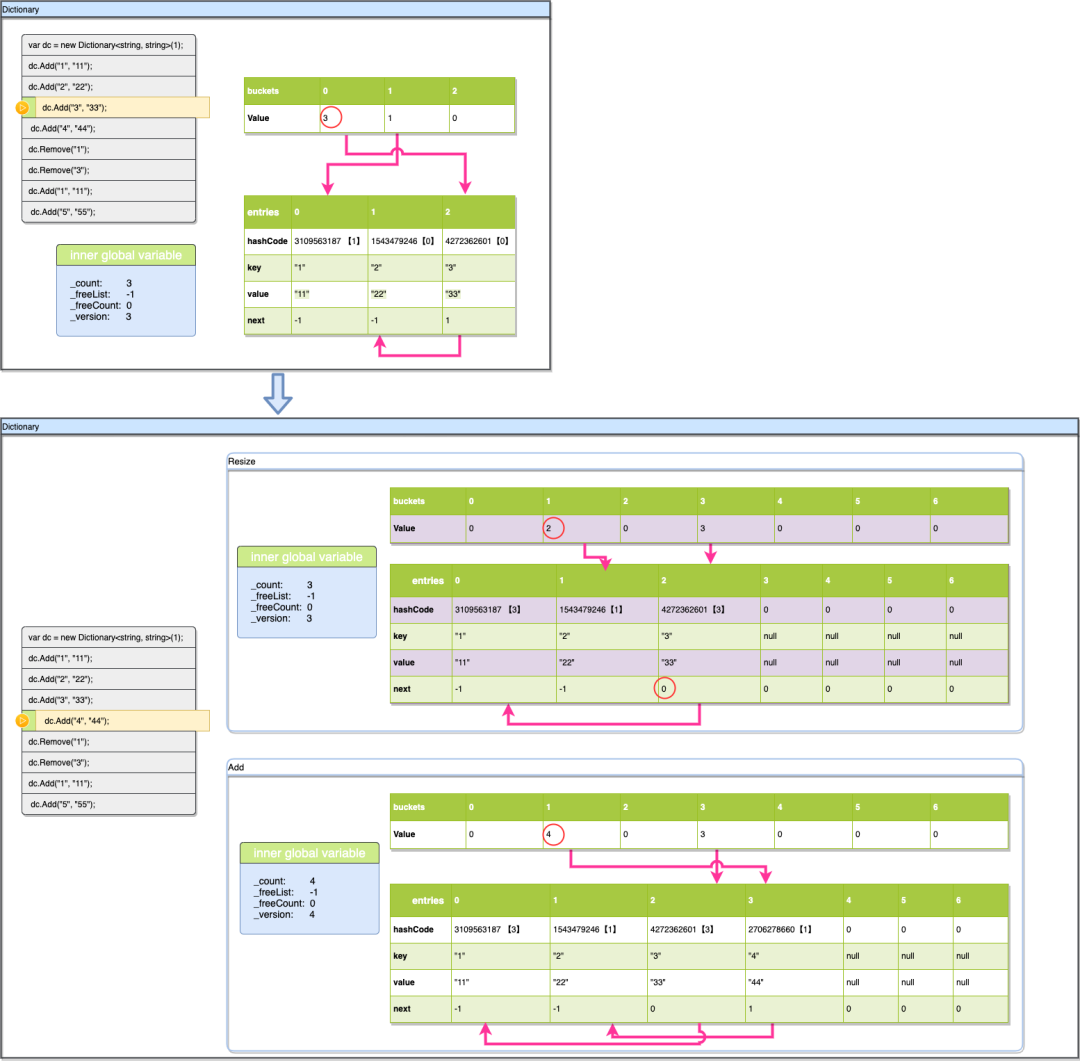
这一次的插入同样会有点特殊,因为我们dictionary开始的容量只有3,现在要插入第4个数据时,我们发现entries已经满了,在插入前,需要先扩容。
-
扩容
前面讲过扩容是按GetPrime(2oldSize)进行的。这里就是取23后面的第一个素数,即为7。所以在扩容时bukets及entries的长度都会变成7,需要在意的是,entries的值是直接复制到新数组后面仅对next做了更新。现在我们来看buckets及元素的next的更新,因为现在dictionary的len已经变了,所以每个元素的hashcode%len的值都会发生变化,槽位信息及碰撞链都会发生改变。之前是0,1这2个槽位被使用,现在变成了1,2。同时可以看到碰撞链也发生了变化(扩容的具体步骤前文中已经有提到)
可以看到因为dictionary的插入是尽可能的顺序插入的,它可以充分利用数组的容量,可以在数组完全满了之后再进行扩容,而HashTable会按负载因子提前很多进行扩容,并且在扩容时dictionary可以尽可能的使用数组复制来完成,而HashTable则几乎是对所有元素重新进行一遍插入。
-
插入
现在开始插入,插入Key:“4”与插入Key:“3”比较类似,在扩容后的entries中Key:“4”与key:“1”的hashcode%len都是1,插入时他们会发生碰撞,同样会生成一个新的碰撞链entries[3]到entries[1],buckets[1]的值也会更新。
4.7、dc.Remove("1")
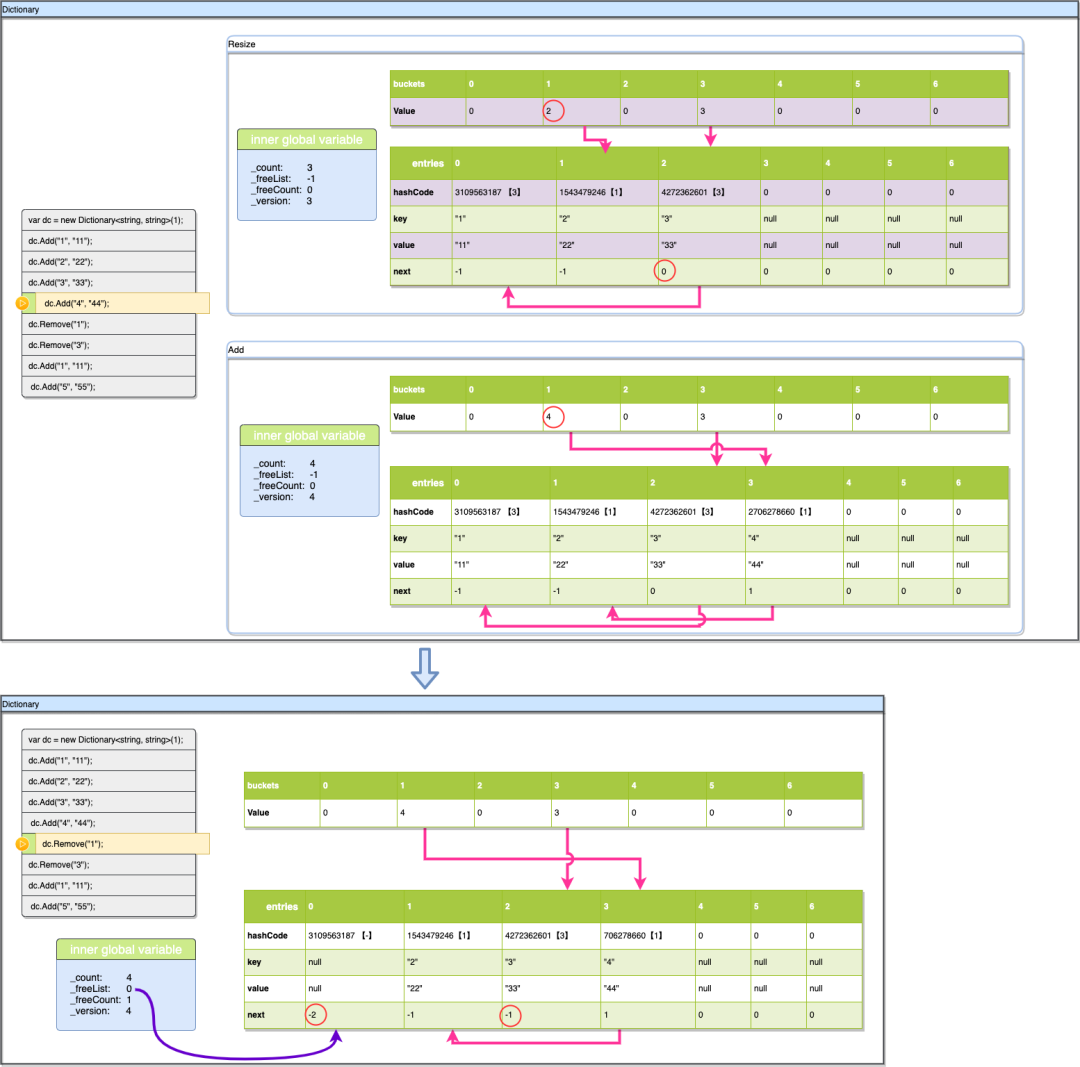
现在我们看一下删除逻辑同时跟踪一下空槽的逻辑,删除Key:“1”也是一样先计算hashcode(key)%len结果是3,通过buckets[3]的值3,可以先找到元素entries[2]进行对比(2是通过buckets[3]-1计算得出),对比Key后发现entries[2].key不是要找的值,继续查找entries[0](0是通过entries[2].next得到),确认entries[0]为目标元素后直接移除key,value对。
有个细节我们通过上图可以看到虽然entries[0]元素是被删除的数据位,不过它的hashCode确并没有更新,因为对于删除后的空位其hashCode不会有任何作用,而我们知道对于值类型的数据entry是直接存储数据本身的,把这个数据置为0会增加开销而产生不了任何作用,而对于引用类型的数据则一定要置为null,因为他们是以引用索引的形式存在entry上的,如果不把这个引用指针断开,这些对象在GC时是将无法被释放。
然后之前entries[2]到entries[0]的碰撞链也随之断开。不过现在entries上有空位产生了,dictionary将_freeList的值设置为刚刚被删除的元素entries[0]的索引0,即表示_freeList对应的元素是最新的空位,注意观察上面「inner global variable」的值,有些值得注意的点,这个_freeList被设置为0刚刚已经提到过了,_freeCount被设置为1,这个也很好理解,空位的数量是1,不过_version这个版本在删除发生后居然并没有+1。
-
_version的作用
先简单理一下_version,他表示的是当前dictionary的版本,在MoveNext()里会有类似代码

可以看到一旦_version发生变化就会报错,MoveNext()主要用在遍历中,最常见的foreach就会用到,所以我们说在遍历时是不能改变集合内容。在我之前的认知里,foreach时新增,修改,删除都是不能进行的,那现在我们看到Remove时_version是没有去改变了,那就是说可以删除了,当即在工程里验证了一下,的确foreach里进行Remove存在并没有报错。
看来之前的认知要改一下了,至少在dotnet core3.0 及以后的版本Dictionary里foreach时是可以Remove的。(其他的版本没有去尝试,大家有兴趣也可以去验证下)
还是一点我们看到_count的值并没有因为删除了一个值而发生变化,其实在dictionary里_count是不会减少的,_count-_freeCount才是集合里元素的数量。
4.8、dc.Remove("3")
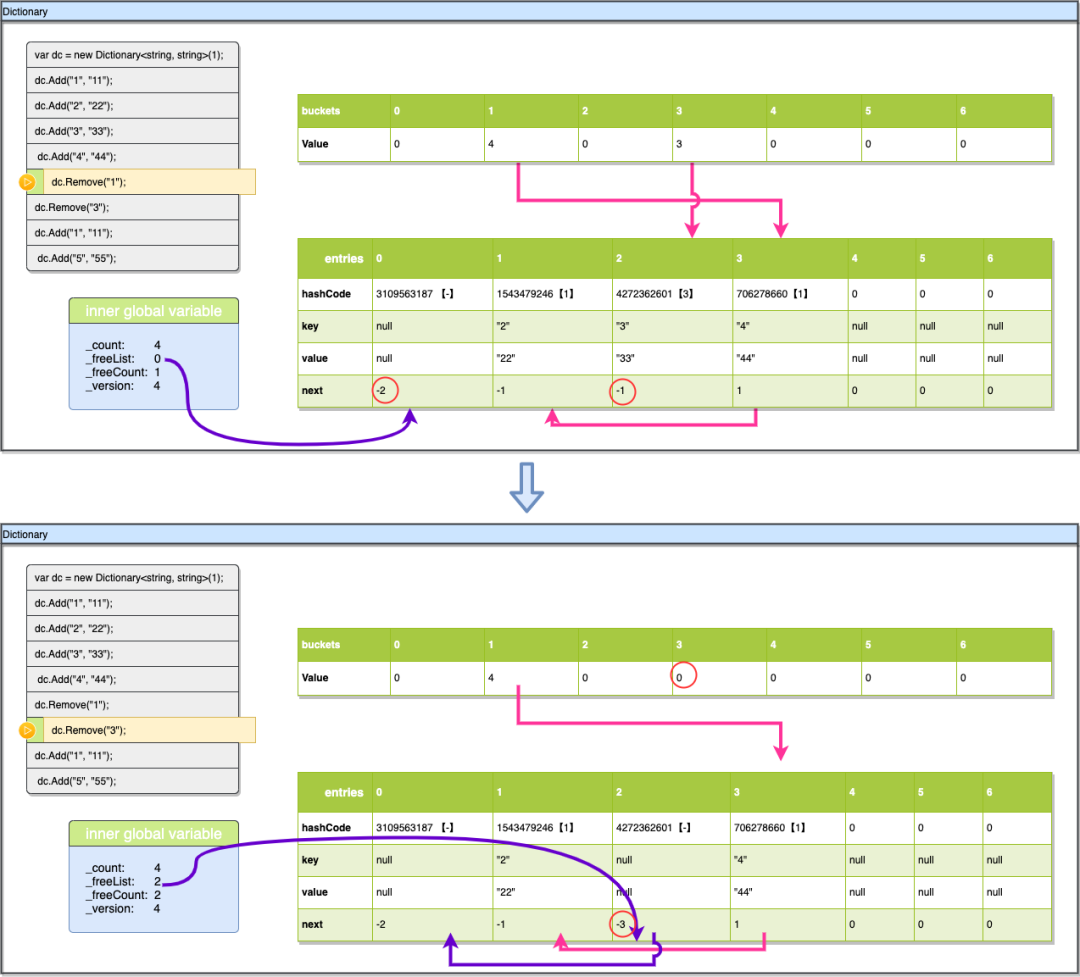
现在我们再删除一个数据,看看空闲链的dictionary里是如何维护的,与前面一步的删除类似,我们先计算Key:“3”的hashcod,hashcod%7=3 我们找到buckets[3]的值3,用3-1的到2,那entries[2]就是我们要找的链首,直接对比entries[2].key发现就是我们要找的元素,与前面的步骤一样移除。不过这里entries[2].next在移除前是-1,代表entries[2]其实是没与集合里的其他元素有碰撞的,所以没有碰撞链需要更新。不过这里还有一点与之前删除Key:“1”不一样,删除Key:“1”时被删除的值是碰撞链里的元素且不是链首,所以其实buckets里的值是不用更新的,不过现在删除的数据没有碰撞链(如果是碰撞链首也是一样处理),所以需要将buckets[3]的值更新为entries[2].next+1即为0。
现在我们来看下空闲链,同样_freeList现在变成了2 指向刚刚被删除的元素,_freeCount也递增1,不过现在有2个空位了,_freeList指向第一个空位,那第二空位(后面的空位)在什么地方,如何标记呢,现在entry的next属性又要发挥作用了,他用StartOfFreeList-next的值来标记空闲链的下一个(StartOfFreeList就是-3 我们可以用 |next|-3 这个来方便表示及计算),这个处理方式前文已经介绍过,这里就不重复描述了。我们直接看到
entries[2].next他现在应该变为StartOfFreeList - _freeList (这个_freeList是之前的_freeList为0)即-3-0=-3,所以我们看到当前的next变成了-3。-3 的指向就是 |-3|-3=0,表示此空位的下一个空位是entries[0]
讲到这里我们可以看出来住dictionary里的entries数组中仅通过next属性就可以完全确认碰撞及空位,整个查找过程都非常简单只是简单的+-操作,而在HashTable中就会相对复杂,由于没有next来标记链HashTable里会反复通过(int)(((long)bucketNumber + incr) % (uint)_buckets.Length类似计算寻找下一个元素进行对比。
4.9、Add("1", "11")
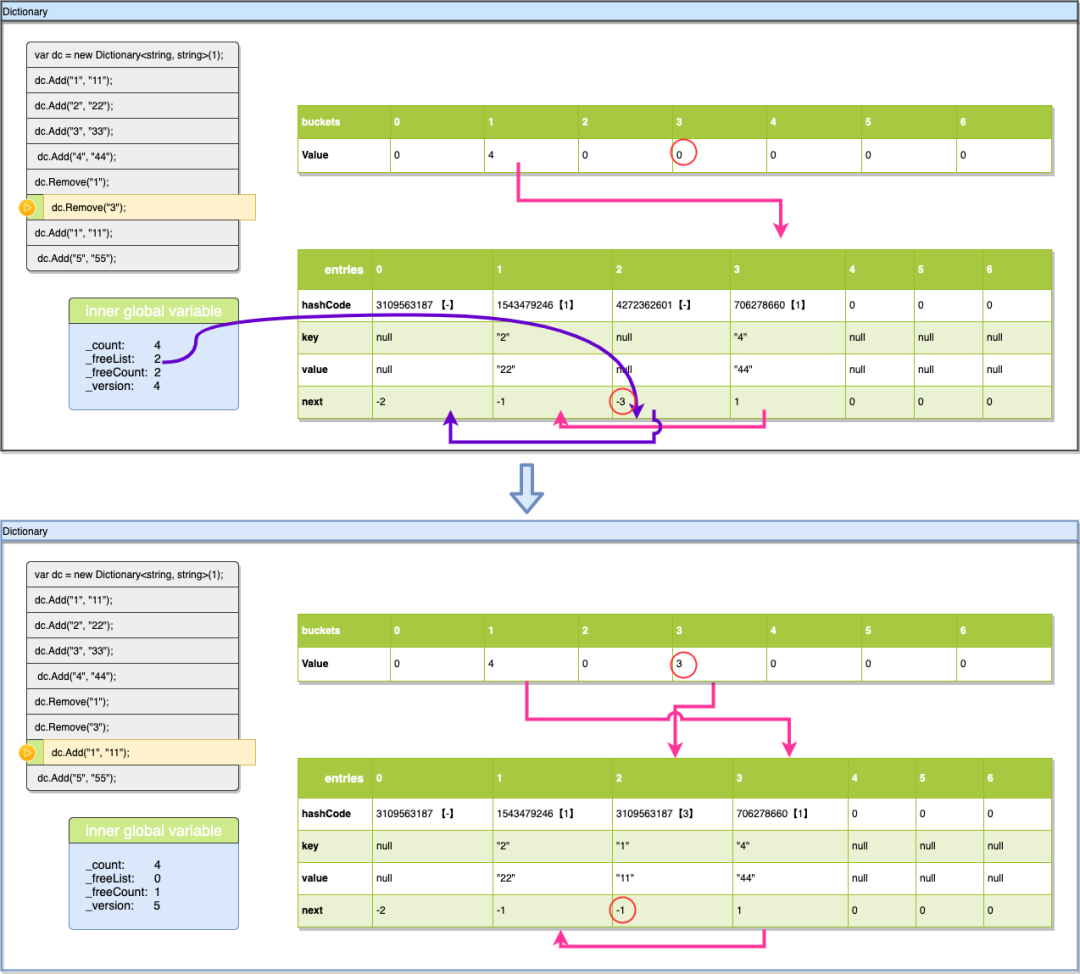
现在我们再把key:“1”加回来,看一下dictionary是如何利用空位的,前面hashcode的操作都是一样的,通过hashcode%7找到buckets[3]他的值是0,表示key:“1”没在集合里没有碰撞,直接插入就可以,之前都是直接插入在entries[_count]下的,不过这次_freeList=2,所以它会先使用空位完成插入,插入完成后将_freeList变为空闲链的下一个(-3-(-3)=0)即为0,然后_version跟之前一样加1,注意这里的_count是同样没有变的,如果用空位_count的值也不会递增。最后buckets[3]的值也要更新为entries[2]的索引+1。
4.10、Add("5", "55")
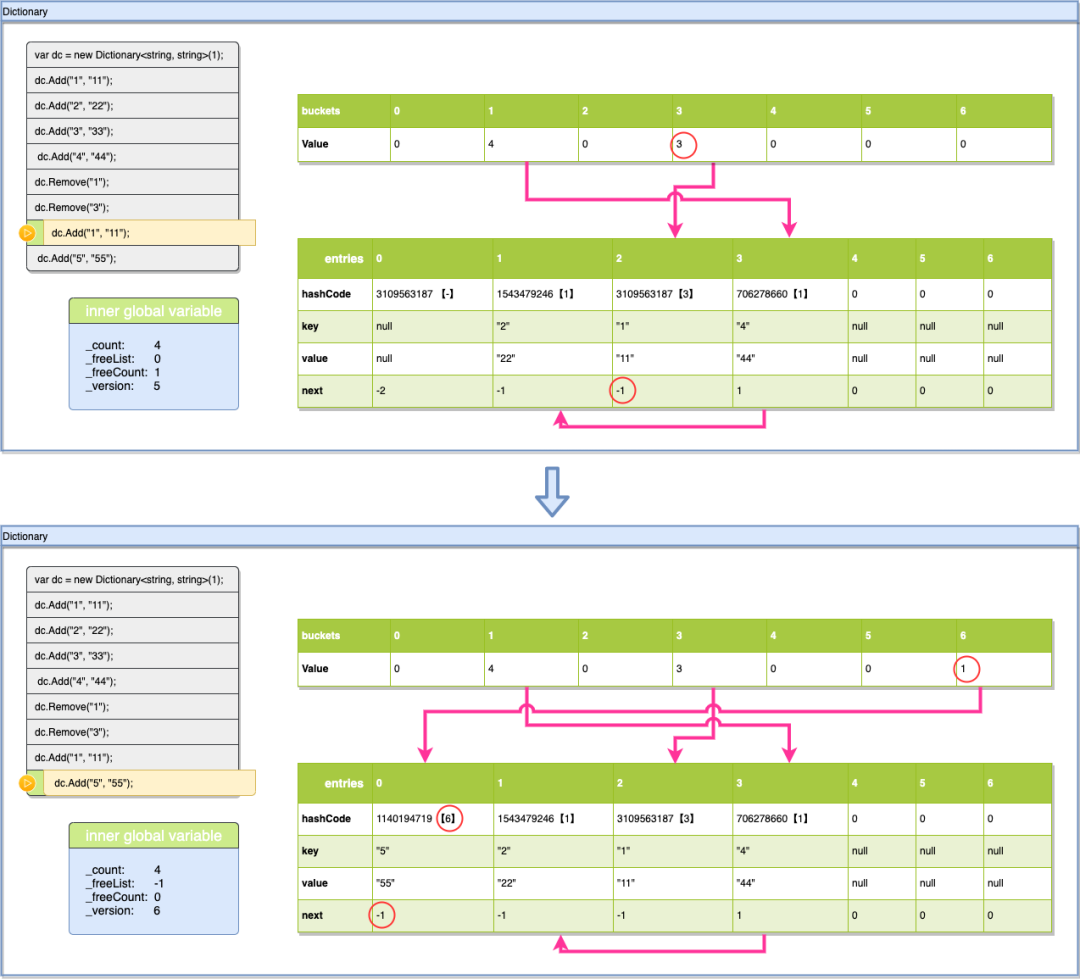
最后一步插入Key:“5”,本次插入会把空位用完,所以_freeList又会变回-1,其他数据的变化之前都描述过(上图红圈标志的地方)这里就不重复讲了,大家可以根据根据前文中讲到的规则自己计算。
五、Dictionary与Hashtable执行速度简单对比
通过以上对Dictionary实际操作,然后又分析了其中每一步其内部主要数据的变化,相信大家会对Dictionary的操作逻辑有个清楚的认识。在上文中会时不时把Dictionary与Hashtable做比较,其实MSDN上已经明确不建议使用HashTable。

-
Dictionary当然除了在泛型上的优势外,由于使用了2个数组维护数据,数据利用率更高,查找,插入,删除都会更快(原因上文其实都有对比提到)。只有在数据量小的时候Hashtable少用一个数组,每个元素也少一个next的属性,其内存占用可能会小一点,不过随着数据存储的越来越多,这个优势会被抹平,因为Dictionary数据数组利用率高。
-
还有一个区别,默认版本Dictionary不是线程安全的,而Hashtable是线程安全的,这意味着Hashtable可以在多个线程在直接被操作,应用开发者不用考虑安全问题。不过这算不上是Hashtable的一个优点,只是它的一个特点,Hashtable在内部实现更新操作有加锁,而Dictionary没有,如果想在多线程条件下操作Dictionary需要自己加锁。
下面对2者读写速度做一个简单对比测试
string[] dataStrs = new string[1000000];
for (int i = 0; i < 1000000; i++)
{
dataStrs[i] = i.ToString();
}
var testDc = new Dictionary<string, string>();
//var testDc = new Hashtable();
Stopwatch sw = new Stopwatch();
Console.WriteLine("any key to start");
Console.ReadLine();
Console.WriteLine("ing......");
for (int j = 0; j < 10; j++)
{
testDc = new Dictionary<string, string>();
//testDc = new Hashtable();
sw.Restart();
sw.Start();
for (int i = 0; i < 1000000; i++)
{
testDc.Add(dataStrs[i], dataStrs[i]);
}
sw.Stop();
Console.WriteLine($"time {sw.ElapsedMilliseconds}");
Console.ReadLine();
}
Console.WriteLine("end of test");
Console.ReadLine();
使用以上代码对Dictionary与Hashtable的插入性能进行简单对比。
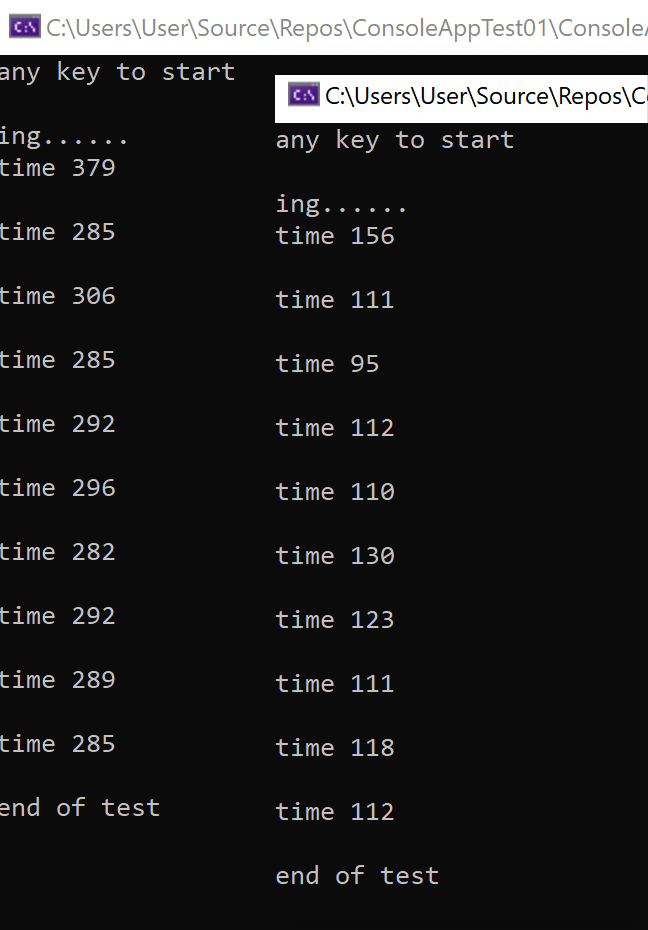
如上图测试结果左边为Hashtable,右边为Dictionary,可以看到仅从插入性能上来看Dictionary的确是要大幅优于Hashtable。
如果您对读取性能进行对比测试也会得到类似结果。
前面已经提过Dictionary借助将buckets槽位信息与entries数据数组分离及对新增next属性的利用让Dictionary的碰撞查找计算量大幅低于Hashtable,同时数据空间的利用率也得到了提高,这也是以上测试结果会有如此大差距的主要原因。
六、后记
篇幅比较长,但是一直都是围绕同一个内容进行讲述。笔者会尽力让描述前后有联系,并避免过多介绍孤立的无关信息。事实上文章的草稿(或者叫个人笔记)一年前就完成了(所以大家也看到调试时其实没有使用最新的.NET6)。
而即便是自己写的内容时隔一年再来回看,也能发现很多细节也并不是读一遍自己就能秒懂的。如果之前没有关注过这些看完会花点时间,但我相信是会有价值的。
本文大多数图表,示例及描述其实也是经过反复修改,并对照实现代码核对或逐行调试而得出来的。
但即便如此限于自身水平或认知上的限制也难免会有错误或不全面的表述,大家在阅读过程中如果发现有纰漏的地方,可以以任何方式提出mycllq@hotmail.com我会在确认后第一时间更正。
