大家好,我是Edison。
去年换工作时系统复习了一下.NET Core多线程相关专题,学习了一线码农老哥的《.NET 5多线程编程实战》课程,我将复习的知识进行了总结形成本专题。
本篇,我们来继续复习一下多线程性能问题的相关知识点,预计阅读时间10分钟。首先,我们可以明确一下,多线程场景下的常见问题一般为:高CPU占用。.
一、CPU暴高问题
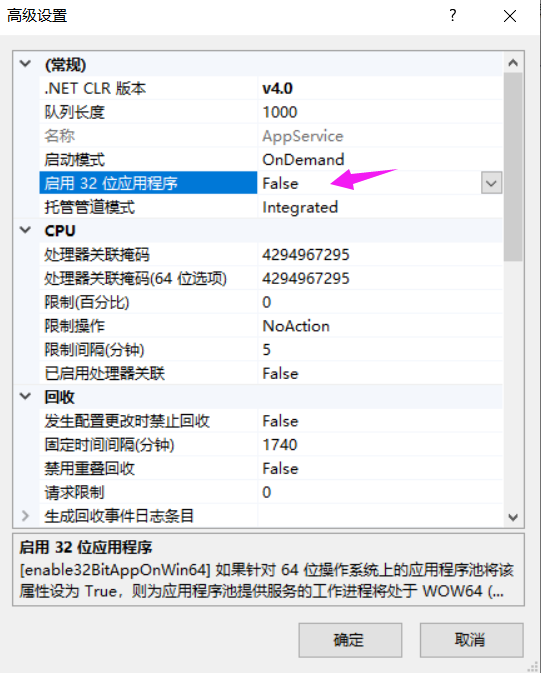
常见于偶发性CPU暴高案例中,比如使用了List.Insert(0, item) 时在大数据量下(比如20w+)时间复杂度很大 + 扩容机制,性能很差!一般可能是由模糊查询导致的查了大量DB数据出来组装,因此只会在大数据量时才会偶发。(2)错误地使用String的拼接导致的CPU暴高大量错误的大字符串(>85K的都会进LOH)拼接导致LOH频繁触发GC导致CPU暴高。建议使用StringBuilder来重构,但要设置一个合适的初始容量Capacity从而避免频繁对象申请和内存复制。(3)非线程安全的Dictionary导致的CPU暴高在多线程环境下使用非线程安全的Dictionary.Contains(key)时导致了在内部实现方法FindEntry(key)时出现了死循环(Entry结构体的next指针指向了自己,由于其他线程也正在Insert、Remove、Update等操作),然后多线程环境下可能有多个死循环一起把CPU打暴了!建议使用线程安全的ConcurrentDictionary结构。(4)lock convoy(锁护送)导致的CPU暴高在多线程环境下频繁的上下文切换导致,比如每个线程被分配了30ms时间片,但只执行了5ms就被卡主了,即每个请求都有一个lock锁。之前Edison所在的Y公司项目中的JSON-RPC的PreRequest就是这种情况。建议使用批量操作,降低串行化的 lock 个数,不要去玩锁内卷。多线程环境下某个方法读取了大量数据(50w+)导致了内存不够用进而引发GC频繁回收进而导致CPU暴高。这常常发生部署在IIS上的.NET Framework Web应用程序:- 32bit的临时代(Gen0+Gen1)大概只有不到100M的内存空间;
- 在IIS服务器模式下,GC会临时征用托管线程充当GC回收线程。
快速解决:将IIS的应用程序域 配置中的 “启用32bit应用程序” 改成False。二、一些实际案例
在Edison的前任Y公司,Edison做了一些性能优化的措施,提高了系统的稳定性。这里假设之前的系统(大单体)域名为 cj.wzy.cn,每天平均UV(独立用户数) 10000~15000个,平均每天PV(页面浏览数)大概20000~25000个,实时用户数UV(高峰期)800~1000个。虽然这个数值并不高,但是对于这个已经运行了7年多的大单体老系统(.NET 4.5)而言,已经是线上很不稳定了,经常可以看到客服发来的客户抱怨的ticket。jsonrpc的全局PreRequest方法中存在大量 lock convoy (锁护送) 导致线程频繁的上下文切换
封装的LocalMemoryCache类基于ReaderWriterLocakSlim对本身就是线程安全的MemoryCache类做线程安全控制
团队以前自己封装的一个 KafkaHelper 的 Send 方法中加锁范围过大导致等待时间较长
......
随着数据量的不断增加,老业务的SQL脚本包含了很多聚合函数、临时表操作 以及 未命中索引的查询条件,解决办法就是SQL优化,对比执行计划 + DBA Review后上线。部分应用服务器特别是自建的文件服务,经常发生由于配置了“启用32位应用程序”导致的内存不够(因为32位应用最大可用4G内存)用进而引发GC频繁回收进而导致CPU暴高。解决办法就是将启用32位应用设为False,然后参考一些IIS配置的最佳实践去做了一遍。当然,根本解法还是去分析自建文件服务中耗内存的地方去优化代码。不过由于当时的物理服务器都是128G的内存且业务场景中也确实存在上传大文件的需求,因此耗内存的地方也暂时搁置去解决了。部分耗时较长的Job不加限制的使用 Parallel.ForEach 等方法造成所有CPU Core都被占用并持续数秒,造成CPU>=90%优化后增加了统一的设置的MaxParallelOptions,修复所有滥用的地方传递进去,默认只会用到CPU内核数量的一半。有一次因为XXXXXReadDB少了一台,本来是1台写库,2台读库,突然少了一台,导致XXXXXReadDB CPU暴高,应用程序段的DB连接超时严重进而造成延时较多,请求对接,应用程序频繁挂掉。因此后续DBA新增了一台读库,组成1主3从的配置,应用程序段通过切分 合同查询 的业务查询 到 XXXXXReadDB04,所有Job的查询都走XXXXXReadDB03,将流量分摊到不同的读库,保证核心用户的查询流量的可用性。2021年开始研发中心内部各团队应用开始疯狂调用该系统接口,每分钟请求量达到了1000+左右,造成了原本只是对外部客户服务的应用服务器压力增大,因此新增了两台应用服务器将所有其他团队的内部应用的service请求流量切分到独立的三台服务器上,内外部客户的流量分开,优先保证外部客户的可用性。这一切的根因都是因为这七年来这个系统所在的团队单纯拼命的干业务迭代,往原本设计就不佳的大单体系统中堆了太多的屎山,造成了太多的技术债并未及时地去偿还。我们也原本想极力推荐将其拆分后升级到.NET Core或最新的.NET技术,基于.NET Core + 容器化技术去做较低成本的升级改造,可是计划赶不上变化,当公司从阿里巴巴找来一些所谓高P来做技术总监之后,所有的计划都是围绕着Java从0到1花费大量成本重构整个大系统来进行,降本增效只能靠Java而不是.NET。公司里整个Java圈子的高级开发者对.NET的认识也还是停留在10年前,我们的发声已变得微不足道,政治正确才是明哲保身的唯一出路。在这里,Edison还是祝愿Y公司能够越走越好,虽然近期听闻研发中心裁员了15%,一些老战友也领到了毕业礼包...