原文 | Stephen Toub
翻译 | 郑子铭
Mono
到目前为止,我一直提到 "JIT"、"GC "和 "运行时",但实际上在.NET中存在多个运行时。我一直在谈论 "coreclr",它是推荐在Linux、macOS和Windows上使用的运行时。然而,还有 "mono",它为Blazor wasm应用程序、Android应用程序和iOS应用程序提供动力。它在.NET 7中也有明显的改进。.
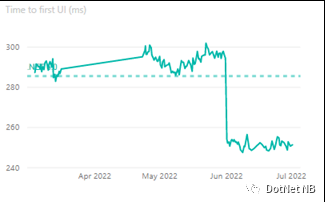
就像coreclr(它可以JIT编译,AOT编译部分JIT回退,以及完全Native AOT编译),mono有多种实际执行代码的方式。其中一种方式是解释器,它使mono能够在不允许JIT的环境中执行.NET代码,而不需要提前编译或招致它可能带来的任何限制。有趣的是,解释器本身几乎就是一个成熟的编译器,它解析IL,为其生成自己的中间表示法 (intermediate representation)(IR),并在IR上进行一次或多次优化;只是在流水线的末端,当编译器通常会发出代码时,解释器却将这些数据保存下来,以便在运行时进行解释。因此,解释器有一个与我们讨论的coreclr的JIT非常相似的难题:优化的时间与快速启动的愿望。在.NET 7中,解释器采用了类似的解决方案:分层编译。 dotnet/runtime#68823增加了解释器的能力,最初编译时对IR进行最小的优化,然后一旦达到一定的调用次数阈值,就花时间对IR进行尽可能多的优化,用于该方法的所有未来调用。这产生了与coreclr相同的好处:改善了启动时间,同时也有高效的持续吞吐量。当这一点合并后,我们看到Blazor wasm应用程序的启动时间改善了10-20%。下面是我们的基准测试系统中正在跟踪的一个应用的例子。
不过,解释器并不只是用于整个应用程序。就像coreclr可以在R2R图像不包含方法的代码时使用JIT一样,mono可以在一个方法没有AOT代码时使用解释器。在mono上发生的这种情况是泛型委托的调用,在这种情况下,泛型委托的调用会触发回落到解释器;对于.NET 7,这种差距已经通过dotnet/runtime#70653解决。然而,一个更有影响的案例是dotnet/runtime#64867。以前,任何带有catch或filter异常处理条款的方法都不能被AOT编译,而会退回到被解释的状态。有了这个PR,方法现在可以被AOT编译,而且只有当异常真正发生时,它才会退回到使用解释器,在该方法调用的剩余执行过程中切换到解释器。由于许多方法都包含这样的条款,这可以使吞吐量和CPU消耗有很大的不同。同样地,dotnet/runtime#63065使带有finally异常处理条款的方法能够被AOT编译;只有finally块被解释,而不是整个方法被解释。
除了这样的后端改进,另一类改进来自coreclr和mono之间的进一步统一。几年前,coreclr和mono有自己的整个库堆栈,建立在它们之上。随着时间的推移,随着.NET的开源,mono的部分栈被共享组件一点一点地取代。时至今日,无论采用哪种运行时,System.Private.CoreLib以上的所有核心.NET库都是一样的。事实上,CoreLib本身的源代码几乎完全是共享的,大约95%的源文件被编译到为每个运行时构建的CoreLib中,只有百分之几的源文件是专门为每个运行时准备的(这些声明意味着本篇文章其余部分讨论的绝大多数性能改进无论在mono和coreclr上运行都同样适用)。即使如此,现在的每一个版本我们都在努力减少剩下的百分之几,这不仅是出于可维护性的考虑,而且还因为从性能的角度来看,用于coreclr的CoreLib的源代码通常会得到更多的关注。例如,dotnet/runtime#71325将mono的数组和跨度排序通用排序工具类转移到coreclr使用的更有效的实现。
然而,最大的改进类别之一是矢量化。这分为两部分。首先,由于dotnet/runtime#64961、dotnet/runtime#65086、dotnet/runtime#65128、dotnet/runtime#66317、dotnet/runtime#66391、dotnet/runtime#66409、dotnet/runtime#66512、 dotnet/runtime#66586、 dotnet/runtime#66589、 dotnet/runtime#66597、 dotnet/runtime#66476和 dotnet/runtime#67125;等PR,Vector和Vector128现在在x64和Arm64上都被完全加速了。 这些大量的工作意味着所有使用这些抽象概念被矢量化的代码在mono和coreclr上都会亮起。其次,主要归功于dotnet/runtime#70086,mono现在知道如何将Vector128操作转换为WASM的SIMD指令集,这样,在Blazor wasm应用程序和其他可能执行WASM的地方,用Vector128矢量化的代码也将被加速。
反射 (Reflection)
反射是那些你要么爱要么恨的领域之一(我发现在写完Native AOT部分后立即写这一节有点幽默)。它的功能非常强大,提供了查询进程中所有代码的元数据和可能遇到的任意程序集的能力,动态调用任意功能,甚至在运行时发出动态生成的IL。面对像链接器这样的工具或像Native AOT这样的解决方案,它也很难很好地处理,因为它需要在构建时准确地确定哪些代码将被执行,而且它在运行时通常相当昂贵;因此它既是我们尽可能避免的东西,也是投资于减少成本的东西,因为它在许多不同类型的应用程序中如此受欢迎,因为它非常有用。与大多数版本一样,它在.NET 7中也有一些不错的改进。
受影响最大的领域之一是反射调用。通过MethodBase.Invoke,这个功能可以让你使用一个MethodBase(例如MethodInfo)对象,该对象代表调用者之前查询过的一些方法,并调用它,带有任意的参数,运行时需要将这些参数传递给被调用者,并带有任意的返回值,需要被传递回来。如果你提前知道方法的签名,优化调用速度的最好方法是通过CreateDelegate从MethodBase中创建一个委托,然后在未来的所有调用中使用该委托。但在某些情况下,你在编译时并不知道签名,因此不能轻易依赖具有已知匹配签名的委托。为了解决这个问题,一些库已经采取了使用反射emit来在运行时生成特定于目标方法的代码。这是很复杂的,我们不希望应用程序必须这样做。相反,在.NET 7中,通过dotnet/runtime#66357、dotnet/runtime#69575和dotnet/runtime#74614,Invoke将自己使用反射emit(以DynamicMethod的形式)生成一个为调用目标而定制的委托,然后未来通过该MethodInfo的调用将利用该生成的方法。这为开发者提供了基于反射mit的自定义实现的大部分性能优势,但在他们自己的代码库中没有这种实现的复杂性或挑战。
private MethodInfo _method;
[GlobalSetup]
public void Setup() => _method = typeof(Program).GetMethod("MyMethod", BindingFlags.NonPublic | BindingFlags.Static);
[Benchmark]
public void MethodInfoInvoke() => _method.Invoke(null, null);
private static void MyMethod() { }
| 方法 | 运行时 | 平均值 | 比率 |
|---|---|---|---|
| MethodInfoInvoke | .NET 6.0 | 43.846 ns | 1.00 |
| MethodInfoInvoke | .NET 7.0 | 8.078 ns | 0.18 |
反射还涉及到对代表类型、方法、属性等的对象的大量操作,在使用这些API时,这里和那里的调整可以增加到一个可衡量的差异。例如,我在过去的性能文章中谈到,我们实现性能提升的方法之一是将本地代码从运行时移植回托管的C#中,这可能是反直觉的。这样做对性能的提升有多种方式,但其中之一是,从托管代码调用到运行时中会有一些开销,而消除这种跳转就可以避免这种开销。这在dotnet/runtime#71873中可以看到充分的效果,它将与Type、RuntimeType(运行时用来表示其类型的Type派生类)和Enum相关的几个 "FCalls "从本地转移到托管。
[Benchmark]
public Type GetUnderlyingType() => Enum.GetUnderlyingType(typeof(DayOfWeek));
| 方法 | 运行时 | 平均值 | 比率 |
|---|---|---|---|
| GetUnderlyingType | .NET 6.0 | 27.413 ns | 1.00 |
| GetUnderlyingType | .NET 7.0 | 5.115 ns | 0.19 |
这种现象的另一个例子是dotnet/runtime#62866,它将AssemblyName的大部分底层支持从本地运行时代码转移到CoreLib的托管代码中。这反过来又对任何使用它的东西产生了影响,比如当使用Activator.CreateInstance重载时,需要解析的汇编名称。
private readonly string _assemblyName = typeof(MyClass).Assembly.FullName;
private readonly string _typeName = typeof(MyClass).FullName;
public class MyClass { }
[Benchmark]
public object CreateInstance() => Activator.CreateInstance(_assemblyName, _typeName);
| 方法 | 运行时 | 平均值 | 比率 |
|---|---|---|---|
| CreateInstance | .NET 6.0 | 3.827 us | 1.00 |
| CreateInstance | .NET 7.0 | 2.276 us | 0.60 |
dotnet/runtime#67148删除了由CreateInstance使用的RuntimeType.CreateInstanceImpl方法内部的几个数组和列表分配(使用Type.EmptyTypes而不是分配一个新的Type[0],避免不必要地将一个构建器变成一个数组,等等),从而减少分配,加快吞吐。
[Benchmark]
public void CreateInstance() => Activator.CreateInstance(typeof(MyClass), BindingFlags.NonPublic | BindingFlags.Instance, null, Array.Empty<object>(), null);
internal class MyClass
{
internal MyClass() { }
}
| 方法 | 运行时 | 平均值 | 比率 | 已分配 | 分配比率 |
|---|---|---|---|---|---|
| CreateInstance | .NET 6.0 | 167.8 ns | 1.00 | 320 B | 1.00 |
| CreateInstance | .NET 7.0 | 143.4 ns | 0.85 | 200 B | 0.62 |
例如,dotnet/runtime#66750更新了AssemblyName.FullName的计算,使用堆栈分配的内存和ArrayPool而不是使用StringBuilder。
private AssemblyName[] _names = AppDomain.CurrentDomain.GetAssemblies().Select(a => new AssemblyName(a.FullName)).ToArray();
[Benchmark]
public int Names()
{
int sum = 0;
foreach (AssemblyName name in _names)
{
sum += name.FullName.Length;
}
return sum;
}
| 方法 | 运行时 | 平均值 | 比率 | 已分配 | 分配比率 |
|---|---|---|---|---|---|
| Names | .NET 6.0 | 3.423 us | 1.00 | 9.14 KB | 1.00 |
| Names | .NET 7.0 | 2.010 us | 0.59 | 2.43 KB | 0.27 |
更多与反射有关的操作也被变成了JIT的内在因素,正如前面讨论的那样,使JIT能够在JIT编译时而不是在运行时计算各种问题的答案。例如,在dotnet/runtime#67852中的Type.IsByRefLike就是这样做的。
[Benchmark]
public bool IsByRefLike() => typeof(ReadOnlySpan<char>).IsByRefLike;
| 方法 | 运行时 | 平均值 | 比率 | 代码大小 |
|---|---|---|---|---|
| IsByRefLike | .NET 6.0 | 2.1322 ns | 1.000 | 31 B |
| IsByRefLike | .NET 7.0 | 0.0000 ns | 0.000 | 6 B |
在benchmarkdotnet的一个警告中指出,.NET 7的版本如此接近于零。
// * Warnings *
ZeroMeasurement
Program.IsByRefLike: Runtime=.NET 7.0, Toolchain=net7.0 -> The method duration is indistinguishable from the empty method duration
而它与一个空方法没有区别,因为它实际上就是这样,我们可以从反汇编中看到。
; Program.IsByRefLike()
mov eax,1
ret
; Total bytes of code 6
还有一些很难看到的改进,但它们消除了作为填充反射缓存的一部分的开销,最终减少了通常在启动路径上所做的工作,帮助应用程序更快地启动。dotnet/runtime#66825、dotnet/runtime#66912和dotnet/runtime#67149都属于这一类别,它们消除了作为收集参数、属性和事件数据一部分的不必要的或重复的数组分配。
互操作 (Interop)
长期以来,.NET对互操作有很好的支持,使.NET应用程序能够消费大量用其他语言编写的功能和/或由底层操作系统暴露的功能。这种支持的基础是 "平台调用 "或 "P/Invoke",在代码中通过应用于方法的[DllImport(..)]表示。DllImportAttribute可以声明一个可以像其他.NET方法一样被调用的方法,但它实际上代表了一些外部方法,当这个管理方法被调用时,运行时应该调用这些方法。DllImport指定了关于该函数在哪个库中的细节,它在该库的导出中的实际名称是什么,关于输入参数和返回值的高级细节,等等,运行时确保所有正确的事情发生。这种机制在所有的操作系统上都适用。例如,Windows有一个方法CreatePipe用于创建匿名管道。
BOOL CreatePipe(
[out] PHANDLE hReadPipe,
[out] PHANDLE hWritePipe,
[in, optional] LPSECURITY_ATTRIBUTES lpPipeAttributes,
[in] DWORD nSize
);
如果我想从C#中调用这个函数,我可以声明一个[DllImport(...)]的对应函数,然后我可以像调用其他托管方法一样调用它。
[DllImport("kernel32", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
private static unsafe extern bool CreatePipe(
out SafeFileHandle hReadPipe,
out SafeFileHandle hWritePipe,
void* lpPipeAttributes,
uint nSize);
这里有几个有趣的事情要注意。有几个参数是可以直接使用的,在管理方和本地方都有相同的表示方法,例如,lpPipeAttributes是一个指针,nSize是一个32位的整数。但是返回值呢?C#中的bool类型(System.Boolean)是一个字节的类型,但是本地签名中的BOOL类型是四个字节;因此调用这个托管方法的代码不能直接调用本地函数,因为需要有一些 "marshalling "逻辑,将四个字节的返回BOOL转换为一个字节的返回bool。同样,本地函数有两个输出指针hReadPipe和hWritePipe,但托管签名声明了两个SafeFileHandles(SafeHandle是一种.NET类型,它包裹着一个指针,并提供一个finalizer和Dispose方法,以确保该指针在不再被使用时被适当地清理)。一些逻辑需要把本地函数产生的输出句柄包进这些SafeFileHandles中,以便从管理方法中输出。那SetLastError = true呢?.NET有Marshal.GetLastPInvokeError()这样的方法,有些代码需要接收这个方法产生的任何错误,并确保它可以通过后续的GetLastPInvokeError()来使用。
如果不需要编排逻辑,例如管理签名和本地签名在所有的意图和目的上都是一样的,所有的参数都是可编排的,所有的返回值都是可编排的,在方法的调用上不需要额外的逻辑,等等,那么[DllImport(...)]最终就是一个简单的穿透,运行时需要做很少的工作来实现它。然而,如果[DllImport(...)]涉及到任何这种编排工作,运行时需要生成一个 "存根",创建一个专门的方法,当[DllImport(...)]被调用时,它将处理所有的输入,委托给实际的本地函数,并且修复所有的输出。该存根在执行时生成,运行时有效地进行反射发射,动态地生成IL,然后进行JIT。
这样做有很多弊端。首先,它需要时间来生成所有的marshalling代码,这些时间可能会对用户体验产生负面影响,比如启动时。第二,其实现的性质抑制了各种优化,如内联。第三,有些平台不允许使用JIT,因为允许动态生成的代码被执行的安全风险(或者在Native AOT的情况下,根本就没有JIT)。第四,这一切都被隐藏起来,使开发人员更难真正理解发生了什么。
但如果这些逻辑都能在构建时而不是在运行时生成呢?生成代码的成本将只在构建时产生,而不是在每个进程执行时产生。这些代码将有效地成为用户代码,拥有所有C#编译器和运行时的优化功能。这些代码将成为应用程序的一部分,能够使用任何理想的AOT系统进行提前编译,无论是crossgen还是Native AOT或其他系统。这些代码是可以检查的,用户可以查看,以了解到底有哪些工作是代表他们完成的。听起来非常令人向往。听起来很神奇。听起来像是前面提到的Roslyn源代码生成器的工作。
.NET 6在.NET SDK中包含了几个源码生成器,而.NET 7在此基础上又增加了几个。其中一个是全新的LibraryImport生成器,它提供的正是我们刚才讨论的神奇的、理想的解决方案。
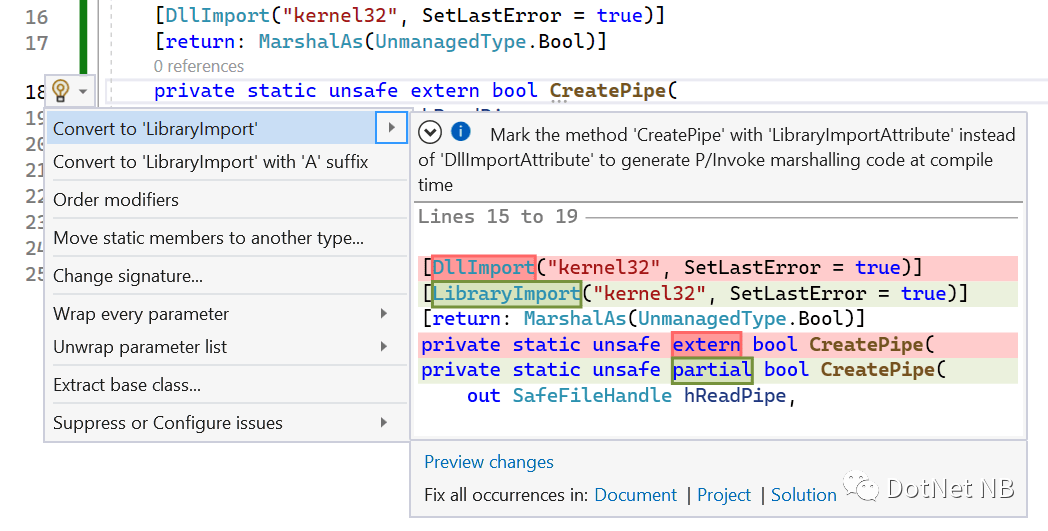
让我们回到我们之前的CreatePipe例子。我们将做两个小调整。我们把属性从DllImport改为LibraryImport,并把extern关键字改为部分。
[LibraryImport("kernel32", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
private static unsafe partial bool CreatePipe(
out SafeFileHandle hReadPipe,
out SafeFileHandle hWritePipe,
void* lpPipeAttributes,
uint nSize);
现在,如果你在家里的Visual Studio中跟随,试着右击CreatePipe并选择Go to Definition。这可能看起来有点奇怪。"转到定义?这不是定义吗?" 这是一个部分方法,这是一种声明的方式,由另一个部分定义来填补,在这种情况下,.NET 7 SDK中的源码生成器注意到了这个带有[LibraryImport]属性的方法,并完全生成了整个C#中的marshalling stub代码,直接构建在程序集中。虽然默认情况下,这些代码不会被持久化,但Visual Studio仍然允许你浏览它(你可以通过在你的.csproj中添加true属性来选择将它持久化在磁盘上)。以下是该方法目前的情况。
[System.CodeDom.Compiler.GeneratedCodeAttribute("Microsoft.Interop.LibraryImportGenerator", "7.0.6.42316")]
[System.Runtime.CompilerServices.SkipLocalsInitAttribute]
private static unsafe partial bool CreatePipe(out global::Microsoft.Win32.SafeHandles.SafeFileHandle hReadPipe, out global::Microsoft.Win32.SafeHandles.SafeFileHandle hWritePipe, void* lpPipeAttributes, uint nSize)
{
int __lastError;
bool __invokeSucceeded = default;
System.Runtime.CompilerServices.Unsafe.SkipInit(out hReadPipe);
System.Runtime.CompilerServices.Unsafe.SkipInit(out hWritePipe);
System.IntPtr __hReadPipe_native = default;
System.IntPtr __hWritePipe_native = default;
bool __retVal;
int __retVal_native = default;
// Setup - Perform required setup.
global::Microsoft.Win32.SafeHandles.SafeFileHandle hReadPipe__newHandle = new global::Microsoft.Win32.SafeHandles.SafeFileHandle();
global::Microsoft.Win32.SafeHandles.SafeFileHandle hWritePipe__newHandle = new global::Microsoft.Win32.SafeHandles.SafeFileHandle();
try
{
{
System.Runtime.InteropServices.Marshal.SetLastSystemError(0);
__retVal_native = __PInvoke(&__hReadPipe_native, &__hWritePipe_native, lpPipeAttributes, nSize);
__lastError = System.Runtime.InteropServices.Marshal.GetLastSystemError();
}
__invokeSucceeded = true;
// Unmarshal - Convert native data to managed data.
__retVal = __retVal_native != 0;
}
finally
{
if (__invokeSucceeded)
{
// GuaranteedUnmarshal - Convert native data to managed data even in the case of an exception during the non-cleanup phases.
System.Runtime.InteropServices.Marshal.InitHandle(hWritePipe__newHandle, __hWritePipe_native);
hWritePipe = hWritePipe__newHandle;
System.Runtime.InteropServices.Marshal.InitHandle(hReadPipe__newHandle, __hReadPipe_native);
hReadPipe = hReadPipe__newHandle;
}
}
System.Runtime.InteropServices.Marshal.SetLastPInvokeError(__lastError);
return __retVal;
// Local P/Invoke
[System.Runtime.InteropServices.DllImportAttribute("kernel32", EntryPoint = "CreatePipe", ExactSpelling = true)]
static extern unsafe int __PInvoke(System.IntPtr* hReadPipe, System.IntPtr* hWritePipe, void* lpPipeAttributes, uint nSize);
}
通过这个,你可以准确地读出正在进行的Marshalling工作。两个SafeHandle实例正在被分配,然后在本地函数完成后,Marshal.InitHandle方法被用来将产生的句柄存储到这些实例中(分配发生在本地函数调用之前,因为如果SafeHandle分配由于超出内存的情况而失败,在本地句柄已经产生后执行分配会增加泄漏的机会)。BOOL到bool的转换是通过!=0的比较进行的。错误信息是通过在本地函数调用后调用Marshal.GetLastSystemError(),然后在返回前调用Marshal.SetLastPInvokeError(int)来获取。实际的本地函数调用仍然通过[DllImport(...)]实现,但现在P/Invoke是可控的,不需要运行时生成任何存根,因为所有这些工作都在这段C#代码中处理了。
为了实现这一点,我们做了大量的工作。去年,我在《.NET 6的性能改进》中提到了其中的一些内容,但在.NET 7中又做了大量的工作,以完善设计,使其实现稳健,在所有的dotnet/runtime和其他地方推广,并向所有的C#开发人员公开这些功能。
LibraryImport生成器是作为dotnet/runtimelab的一个实验开始的。当它准备就绪时,dotnet/runtime#59579将180个跨越多年的努力提交到dotnet/runtime主分支。
在.NET 6中,整个核心.NET库有近3000个[DllImport]的使用。截至我写这篇文章时,在.NET 7中,有......让我搜索一下......7个(我希望可以说是0个,但还有一些零星的,主要与COM互操作有关,仍然存在)。这并不是一夜之间发生的转变。大量的PR逐个库进行了新旧转换,例如dotnet/runtime#62295和dotnet/runtime#61640,用于System.Private.CoreLib,dotnet/runtime#61742和dotnet/runtime#62309用于加密库,dotnet/runtime#61765用于网络,dotnet/runtime#61996和dotnet/runtime#61638用于大多数其他I/O相关的库,还有dotnet/runtime#61975,dotnet/runtime#61389, dotnet/runtime#62353, dotnet/runtime#61990, dotnet/runtime#61949, dotnet/runtime#61805, dotnet/runtime#61741, dotnet/runtime#61184, dotnet/runtime#54290, dotnet/runtime#62365, dotnet/runtime#61609, dotnet/runtime#61532, and dotnet/runtime#54236 中的长尾部分的额外移植。
如果有一个工具来帮助实现自动化,这样的移植工作就会变得非常容易。 dotnet/runtime#72819启用了分析器和固定器来执行这些转换。
还有很多其他的PR,使LibraryImport生成器成为.NET 7的现实。为了突出一些,dotnet/runtime#63320引入了一个新的[DisabledRuntimeMarshalling]属性,可以在程序集级别指定,以禁用所有运行时内置的marshalling;在这一点上,作为互操作的一部分进行的唯一marshalling是在用户的代码中进行的marshalling,例如,由[LibraryImport]生成。其他PR如dotnet/runtime#67635和dotnet/runtime#68173增加了新的编排类型,包括常见的编排逻辑,并且可以从[LibraryImport(...)]中引用,用于定制编排的执行方式(生成器是基于模式的,并允许通过提供实现正确形状的类型来定制编排,这些类型支持最常见的编排需要)。真正有用的是,dotnet/runtime#71989增加了对marshaling {ReadOnly}Span的支持,这样spans就可以直接用于[LibraryImport(..)]方法签名中,就像数组一样(dotnet/runtime中的例子可以在dotnet/runtime#73256中找到。)。dotnet/runtime#69043整合了运行时在[DllImport]中的marshalling支持和[LibraryImport]的生成器支持之间的逻辑共享。
还有一类与互操作相关的变化,我认为值得一谈的是与SafeHandle的清理有关。作为一个提醒,SafeHandle的存在是为了缓解围绕管理本地句柄和文件描述符的各种问题。一个本地句柄或文件描述符只是一个内存地址或数字,它指的是一些拥有的资源,当它用完后必须被清理/关闭。一个SafeHandle的核心只是一个管理对象,它包装了这样一个值,并提供了一个Dispose方法和一个关闭它的终结器。这样,如果你为了关闭资源而忽略了SafeHandle的处置,当SafeHandle被垃圾回收和最终运行它的终结器时,资源仍然会被清理掉。然后,SafeHandle还提供了一些围绕该关闭的同步,试图尽量减少资源在仍在使用时被关闭的可能性。它提供了DangerousAddRef和DangerousRelease方法,分别递增和递减一个参考计数,如果在参考计数高于0时调用Dispose,由Dispose触发的实际释放句柄将被推迟到参考计数回到0。当你把一个SafeHandle传入一个P/Invoke时,该P/Invoke的生成代码会处理调用DangerousAddRef和DangerousRelease(由于我已经颂扬过LibraryImport的神奇之处,你可以很容易地看到这一点,比如在前面的生成代码例子中)。我们的代码努力在SafeHandles之后确定地进行清理,但很容易意外地留下一些用于最终处理。
dotnet/runtime#71854给SafeHandle添加了一些只用于调试的跟踪代码,使在dotnet/runtime工作的开发人员(或更具体地说,使用运行时的检查构建的开发人员)更容易发现此类问题。当SafeHandle被构建时,它捕获了当前的堆栈跟踪,如果SafeHandle被最终确定,它将堆栈跟踪转储到控制台,使我们很容易看到最终被最终确定的SafeHandle是在哪里创建的,以便跟踪它们并确保它们被处理掉。从这个涉及150多个文件和近1000行代码的PR中可能可以看出,有不少地方从清理中受益。现在,公平地说,其中许多是在特殊的代码路径上。例如,考虑一个假想的P/Invoke,比如。
[LibraryImport("SomeLibrary", SetLastError = true)]
internal static partial SafeFileHandle CreateFile();
和使用它的代码,如。
SafeFileHandle handle = Interop.CreateFile();
if (handle.IsInvalid)
{
throw new UhOhException(Marshal.GetLastPInvokeError());
}
return handle;
看上去很直接。除了这段代码实际上会在失败路径上留下一个SafeHandle用于最终处理。SafeHandle里面有一个无效的句柄并不重要,它仍然是一个可最终确定的对象。为了处理这个问题,这段代码会被更稳健地写成。
SafeFileHandle handle = Interop.CreateFile();
if (handle.IsInvalid)
{
int lastError = Marshal.GetLastPInvokeError();
handle.Dispose(); // or handle.SetHandleAsInvalid()
throw new UhOhException(lastError);
}
return handle;
这样一来,即使在失败的情况下,这个SafeHandle也不会产生最终的压力。还要注意的是,作为增加Dispose调用的一部分,我也把Marshal.GetLastPInvokeError()移了上去。这是因为在SafeHandle上调用Dispose可能最终会调用SafeHandle的ReleaseHandle方法,而SafeHandle派生类型的开发者将重载该方法以关闭资源,这通常涉及到另一个P/Invoke。如果这个P/Invoke有SetLastError=true,它就可以覆盖我们要抛出的错误代码。因此,一旦我们知道互操作调用失败,我们就立即访问并存储最后的错误,然后清理,最后才抛出。综上所述,在那个PR中,有许多地方的SafeHandles甚至在成功路径上也被留作最终确定。dotnet/runtime#71991、dotnet/runtime#71854、dotnet/runtime#72116、dotnet/runtime#72189、dotnet/runtime#72222、dotnet/runtime#72203和dotnet/runtime#72279都发现并修复了许多SafeHandles被留作最终处理的情况(这要感谢前面提到的PR中的诊断措施)。
dotnet/runtime#70000来自@huoyaoyuan,将几个与委托相关的 "FCalls "从本地代码中实现改写为托管,从而减少了调用这些操作时的开销,这些操作通常涉及到Marshal.GetDelegateForFunctionPointer的场景。 dotnet/runtime#68694也将一些琐碎的功能从本地转移到托管,作为放松对使用钉子手柄 (pinning handles) 的参数验证的一部分。这反过来又极大地减少了使用GCHandle.Alloc来处理这种钉子手柄的开销。
private byte[] _buffer = new byte[1024];
[Benchmark]
public void PinUnpin()
{
GCHandle.Alloc(_buffer, GCHandleType.Pinned).Free();
}
| 方法 | 运行时 | 平均值 | 比率 | 代码大小 |
|---|---|---|---|---|
| PinUnpin | .NET 6.0 | 37.11 ns | 1.00 | 353 B |
| PinUnpin | .NET 7.0 | 32.17 ns | 0.87 | 232 B |
线程 (Threading)
线程是影响每个应用程序的跨领域问题之一,因此,线程领域的变化会产生广泛的影响。在这个版本中,ThreadPool本身有两个非常大的变化;dotnet/runtime#64834将 "IO池 "转为使用一个完全受管的实现(而之前的IO池仍然在本地代码中,尽管在以前的版本中工作者池已经完全转为受管),dotnet/runtime#71864同样将定时器的实现从基于本地代码转为完全受管代码。这两个变化会影响性能,前者在较大的硬件上被证明了,但在大多数情况下,这并不是他们的主要目标。相反,其他的PR一直专注于提高吞吐量。
其中一个问题是dotnet/runtime#69386。线程池有一个 "全局队列",任何线程都可以将工作排入其中,然后池中的每个线程都有自己的 "本地队列"(任何线程都可以从该队列中退出,但只有所属线程可以排入)。当一个工作者需要处理另一个工作时,它首先检查自己的本地队列,然后检查全局队列,然后只有当它在这两个地方都找不到工作时,它才去检查所有其他线程的本地队列,看看它是否能帮助减轻它们的负担。随着机器规模的扩大,拥有越来越多的内核和越来越多的线程,这些共享队列,特别是全局队列上的争夺就越来越多。这个PR通过在机器达到一定的阈值(现在是32个处理器)时引入额外的全局队列来解决这些大型机器的问题。这有助于在多个队列中划分访问,从而减少争论。
另一个是dotnet/runtime#57885。为了协调线程,当工作项目被排队和取消排队时,池子向其线程发出请求,让它们知道有工作可以做。然而,这往往会导致超额认购,更多的线程会争先恐后地试图获得工作项目,特别是在系统没有满负荷的时候。这反过来又会表现为吞吐量的下降。这一变化彻底改变了线程的请求方式,即每次只请求一个额外的线程,在该线程取消其第一个工作项目后,如果有剩余的工作,它可以发出一个额外线程的请求,然后该线程可以发出一个额外的请求,以此类推。下面是我们的性能测试套件中的一个性能测试(我把它简化了,从测试中删除了一堆配置选项,但它仍然是准确的配置之一)。乍一看,你可能会想,"嘿,这是一个关于ArrayPool的性能测试,为什么它会出现在线程讨论中?" 而且,你会是对的,这是一个专注于ArrayPool的性能测试。然而,正如前面提到的,线程影响着一切,在这种情况下,中间的那个await Task.Yield()导致这个方法的剩余部分被排到ThreadPool中执行。由于测试的结构,做 "真正的工作",与线程池中的线程竞争CPU周期,以获得他们的下一个任务,它显示了移动到.NET 7时的可衡量的改进。
private readonly byte[][] _nestedArrays = new byte[8][];
private const int Iterations = 100_000;
private static byte IterateAll(byte[] arr)
{
byte ret = default;
foreach (byte item in arr) ret = item;
return ret;
}
[Benchmark(OperationsPerInvoke = Iterations)]
public async Task MultipleSerial()
{
for (int i = 0; i < Iterations; i++)
{
for (int j = 0; j < _nestedArrays.Length; j++)
{
_nestedArrays[j] = ArrayPool<byte>.Shared.Rent(4096);
_nestedArrays[j].AsSpan().Clear();
}
await Task.Yield();
for (int j = _nestedArrays.Length - 1; j >= 0; j--)
{
IterateAll(_nestedArrays[j]);
ArrayPool<byte>.Shared.Return(_nestedArrays[j]);
}
}
}
| 方法 | 运行时 | 平均值 | 比率 |
|---|---|---|---|
| MultipleSerial | .NET 6.0 | 14.340 us | 1.00 |
| MultipleSerial | .NET 7.0 | 9.262 us | 0.65 |
在ThreadPool之外,也有一些改进。一个显著的变化是对AsyncLocals的处理,在dotnet/runtime#68790。AsyncLocal与ExecutionContext紧密结合;事实上,在.NET Core中,ExecutionContext完全是为了流动AsyncLocal实例。一个ExecutionContext实例维护着一个单一的字段,即map数据结构,它存储了所有AsyncLocal的数据,并在该上下文中存在数据。每个 AsyncLocal 都有一个作为键的对象,对该 AsyncLocal 的任何获取或设置都表现为获取当前的 ExecutionContext,在上下文的字典中查找该 AsyncLocal 的键,然后返回它找到的任何数据,或者在设置器的情况下,用更新的字典创建一个新的 ExecutionContext 并发布回来。因此,这个字典需要非常有效地进行读写,因为开发者希望 AsyncLocal 的访问尽可能快,常常把它当作其他的局部来对待。所以,为了优化这些查找,该字典的表示法会根据这个上下文中AsyncLocal的数量来改变。对于最多三个项目,我们使用了专门的实现,为三个键和值中的每一个提供字段。超过16个元素,则使用键/值对的数组。再往上,则使用一个Dictionary<,>。在大多数情况下,这样做效果很好,大多数ExecutionContexts能够用前三种类型中的一种表示许多流量。然而,事实证明,四个活跃的AsyncLocal实例真的很常见,特别是在ASP.NET中,ASP.NET基础设施本身使用了几个。所以,这个PR采取了复杂的打击,为四个键/值对增加了一个专门的类型,以便从一个到四个的优化,而不是一个到三个。虽然这提高了一点吞吐量,但它的主要意图是改善分配,这比.NET 6提高了20%。
private AsyncLocal<int> asyncLocal1 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal2 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal3 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal4 = new AsyncLocal<int>();
[Benchmark(OperationsPerInvoke = 4000)]
public void Update()
{
for (int i = 0; i < 1000; i++)
{
asyncLocal1.Value++;
asyncLocal2.Value++;
asyncLocal3.Value++;
asyncLocal4.Value++;
}
}
| 方法 | 运行时 | 平均值 | 比率 | 代码大小 | 已分配 | 分配比率 |
|---|---|---|---|---|---|---|
| Update | .NET 6.0 | 61.96 ns | 1.00 | 1,272 B | 176 B | 1.00 |
| Update | .NET 7.0 | 61.92 ns | 1.00 | 1,832 B | 144 B | 0.82 |
另一个有价值的修复是针对dotnet/runtime#70165中的锁定。这个特别的改进有点难以用benchmarkdotnet来演示,所以只要试着运行这个程序,先在.NET 6上,然后在.NET 7上。
using System.Diagnostics;
var rwl = new ReaderWriterLockSlim();
var tasks = new Task[100];
int count = 0;
DateTime end = DateTime.UtcNow + TimeSpan.FromSeconds(10);
while (DateTime.UtcNow < end)
{
for (int i = 0; i < 100; ++i)
{
tasks[i] = Task.Run(() =>
{
var sw = Stopwatch.StartNew();
rwl.EnterReadLock();
rwl.ExitReadLock();
sw.Stop();
if (sw.ElapsedMilliseconds >= 10)
{
Console.WriteLine(Interlocked.Increment(ref count));
}
});
}
Task.WaitAll(tasks);
}
这只是简单地启动了100个任务,每个任务都进入和退出一个读写锁,等待所有的任务,然后重新做这个过程,持续10秒。它还会计算进入和退出锁所需的时间,如果它不得不等待至少15ms,就会写一个警告。当我在.NET 6上运行这个程序时,我得到了大约100次进入/退出锁的时间>=10ms的情况。而在.NET 7上,我得到的是0次出现。为什么会有这种差别?ReaderWriterLockSlim的实现有它自己的自旋循环实现,该自旋循环试图将各种事情混在一起做,从调用Thread.SpinWait到Thread.Sleep(0)到Thread.Sleep(1)。问题出在Thread.Sleep(1)上。这是说 "让这个线程休眠1毫秒";然而,操作系统对这样的时间安排有最终的决定权,在Windows上,默认情况下,这个休眠会接近15毫秒(在Linux上会低一点,但仍然相当高)。因此,每次在锁上出现足够的争夺,迫使它调用Thread.Sleep(1)时,我们就会产生至少15毫秒的延迟,甚至更多。前面提到的PR通过消除对Thread.Sleep(1)的使用来解决这个问题。
最后要指出的是与线程有关的变化:dotnet/runtime#68639。这个是Windows特有的。Windows有处理器组的概念,每个处理器组最多可以有64个内核,默认情况下,当一个进程运行时,它被分配到一个特定的处理器组,只能使用该组中的内核。在.NET 7中,运行时翻转其默认值,因此默认情况下,如果可能的话,它会尝试使用所有处理器组。
原文链接
Performance Improvements in .NET 7
