引言
最近做一个功能想要动态执行C#脚本,就是预先写好代码片段,在程序运行时去执行代码段,比如像这样(以下代码为伪代码):
string scriptText = "int a = 1;int b = 2; return a+b ;";
var result = Script.Run(scriptText);
查阅了一些资料,发现 .Net的开源编译器平台 - 「Roslyn」,可以支持这样的功能。.
其实 「Roslyn」 提供了很多强大的功能,比如:
-
提供了一组丰富的 API,允许开发人员在运行时动态地生成、编译和执行代码。这些 API 分为两类:编译 API 和工作空间 API。编译 API 用于分析和生成代码,工作空间 API 用于与集成开发环境(IDE)进行交互。通过这些 API,开发人员可以构建强大的代码分析和重构工具。 -
支持对源代码进行静态分析,以便在编译期间检测潜在的代码问题。也支持编写自定义诊断和代码修复,这使得开发人员可以根据自己的需求创建特定的诊断和修复工具。 -
Roslyn 支持 C# 和 VB.NET 两种编程语言。它提供了一组通用 API,这样两种语言之间共享代码就变得容易。 -
Roslyn 与 Visual Studio、Visual Studio Code 和其他支持 C# 和 VB.NET 的 IDE 集成很好。
Roslyn概述
因为现在需要它的动态编译,动态执行代码的功能,所以先仔细了解一下,看一下它的官方概述(https://github.com/dotnet/roslyn/blob/main/docs/wiki/Roslyn-Overview.md) 因为官方概述是英文版,所以我将他翻译为了中文:
概述内容包括:
-
介绍 -
公开的编译器API -
编译器 API(Compiler APIs) -
诊断 API(Diagnostic APIs) -
脚本 API (Scripting APIs) -
工作区 API(Workspaces APIs) -
编译器流水线功能区域(Compiler Pipeline Functional Areas) -
API层
-
-
使用语法 -
语法树(Syntax Trees) -
语法节点(Syntax Nodes) -
语法标记(Syntax Token) -
语法琐事(Syntax Trivia) -
跨度(Spans) -
种类(Kinds) -
错误(Error)
-
-
使用语义 -
汇编(Compilation) -
符号(Symbols) -
语义模型(Semantic Model)
-
-
使用工作区 -
工作区(Workspace) -
解决方案,项目和文档(Solutions, Projects and Documents)
-
介绍
传统上来说,编译器就是黑盒 -- 源代码进入一端,经过一些神奇的过程,然后输出目标文件或者汇编代码。
编译器会对代码进行深入的理解,但这些知识只有编译器实现者才能使用。然而,现在我们越来越多地依赖于集成开发环境(IDE)的功能,如智能提示、重构、智能重命名、查找引用和转到定义等,以提高工作效率。我们还使用代码分析工具来改善代码质量,使用代码生成工具来辅助构建应用程序。
随着这些工具变得越来越智能,它们需要访问编译器所具有的深层代码知识。这就是 Roslyn的核心任务:打开这些黑盒子,让工具和终端用户能够分享编译器对代码的丰富信息。
通过Roslyn,编译器成为一个平台,提供API供工具和应用程序使用,而不仅仅是将源代码翻译为目标代码的工具。这种过渡降低了创建面向代码的工具和应用程序的门槛,为元编程、代码生成和转换、交互式使用C#和VB语言以及将C#和VB嵌入领域特定语言等领域的创新提供了机会。
Roslyn SDK预览版包含了用于代码生成、分析和重构的最新语言对象模型的草案。
我们希望在未来的预览版中包含用于脚本编写和交互使用C#和Visual Basic的API支持的草案。本文提供了Roslyn的概念概述。更多细节可以在SDK预览版中的演练和示例中找到。
公开的编译器API
编译器流水线功能区域(Compiler Pipeline Functional Areas)
Roslyn通过提供与传统编译器流水线相对应的API层,将C#和Visual Basic编译器的代码分析暴露给开发者作为使用者。

该流水线的每个阶段现在都是一个单独的组件。首先是解析阶段,源代码被标记化并解析为符合语言语法的语法结构。其次是声明阶段,对源代码和导入的元数据进行分析,形成命名符号。接下来是绑定阶段,将代码中的标识符与符号进行匹配。最后是发出阶段,编译器构建的所有信息作为一个程序集进行输出。
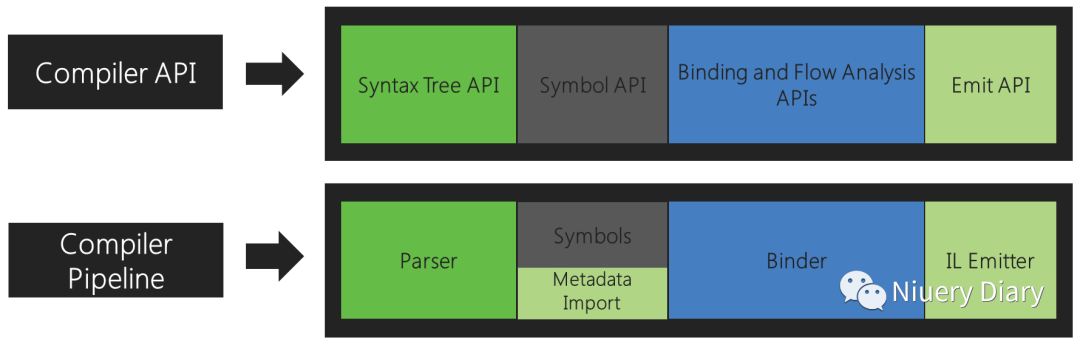
针对每个阶段,都有一个相应的对象模型,允许访问该阶段的信息。解析阶段以语法树的形式暴露,声明阶段以层次化符号表的形式暴露,绑定阶段以显示编译器语义分析结果的模型形式暴露,发出阶段以生成IL字节码的API形式暴露。
 编译器将这些组件组合为一个单一的端到端整体。
编译器将这些组件组合为一个单一的端到端整体。
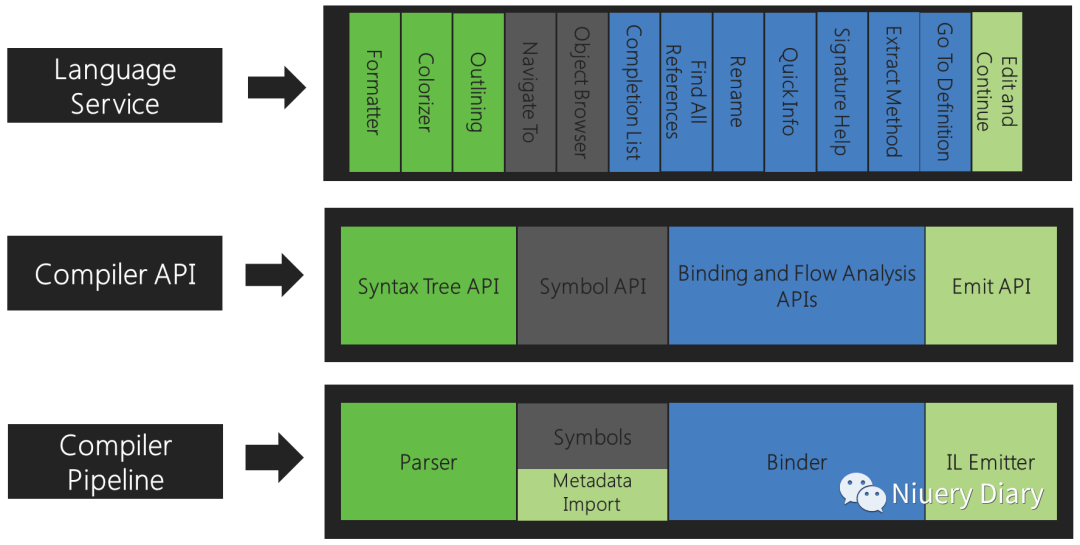
为了确保公开的编译器API足以构建世界一流的IDE功能,将使用这些API重建用于支持Visual Studio vNext中的C#和VB体验的语言服务。
例如,代码大纲和格式化功能使用语法树,对象浏览器和导航功能使用符号表,重构和转到定义使用语义模型,编辑和继续使用所有这些功能,包括发出API。
这些体验可以在Visual Studio 2013上通过“Roslyn”终端用户预览版中预览。这个预览版是为了构建和测试基于Roslyn SDK的应用程序,并用于集成到Visual Studio中。但是,不需要终端用户预览版,可以独立于Visual Studio在自己的应用程序中使用Roslyn API。
API 层
Roslyn由两个主要的API层组成——编译器API和工作区API。
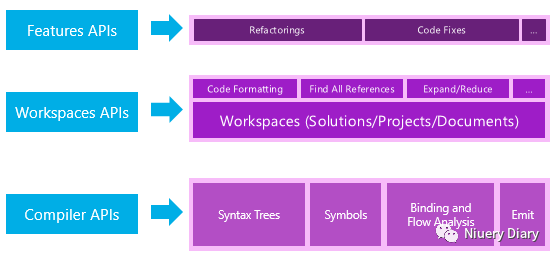
编译器 API(Compiler APIs)
编译器层包含与编译器流水线的每个阶段对应的对象模型,包括语法和语义信息。编译器层还包含编译器单次调用的不可变快照,包括程序集引用、编译器选项和源代码文件。
C#语言和Visual Basic语言有两个不同的API表示。这两个API在形式上类似,但为每种语言进行了高保真度的定制。
该层不依赖于Visual Studio组件。
诊断 API(Diagnostic APIs)
作为分析的一部分,编译器可以生成一组诊断信息,涵盖从语法、语义和明确赋值错误到各种警告和信息性诊断的所有内容。
编译器API层通过可扩展的API公开诊断信息,允许用户定义的分析器插入到编译中,并产生用户定义的诊断,例如由StyleCop或FxCop等工具生成的诊断,与编译器定义的诊断一起产生。
以这种方式生成诊断信息的好处是与诸如MSBuild和Visual Studio等工具自然集成,这些工具依赖于诊断信息,用于诸如基于策略停止构建、在编辑器中显示实时波浪线和建议代码修复等功能。
脚本 API (Scripting APIs)
作为编译器层的一部分,团队创建了用于执行代码片段和累积运行时执行上下文的托管/脚本API。REPL(交互式编程环境)使用这些API。
工作区 API(Workspaces APIs)
工作区层包含Workspace API,用于对整个解决方案进行代码分析和重构的起点。它有助于将解决方案中的所有项目的信息组织成单个对象模型,并直接访问编译器层的对象模型,无需解析文件、配置选项或管理项目之间的依赖关系。
此外,工作区层还提供一组常用的API,用于在类似Visual Studio IDE的宿主环境中实现代码分析和重构工具,例如“查找所有引用”、“格式化”和“代码生成”等API。
该层不依赖于Visual Studio组件。
使用语法
编译器API公开的最基本数据结构是语法树。这些树表示源代码的词法和语法结构。它们具有两个重要目的:
-
允许工具(如集成开发环境、插件、代码分析工具和重构工具)查看和处理用户项目中源代码的语法结构。 -
可以让工具(如重构工具和集成开发环境)以自然的方式创建、修改和重新排列源代码,而无需直接进行文本编辑。通过创建和操作语法树,工具可以轻松地创建和重新排列源代码。
语法树(Syntax Trees)
语法树是用于编译、代码分析、绑定、重构、集成开发环境功能和代码生成的主要结构。没有将源代码首先识别和分类为众多已知结构化语言元素之一,就无法理解源代码的任何部分。
语法树具有三个关键属性。第一个属性是语法树以完全保真度保存所有的源信息。这意味着语法树包含源文本中的每个信息片段,每个语法构造,每个词法标记,以及包括空格、注释和预处理指令在内的其他内容。例如,源代码中提到的每个字面值都会按照其输入方式进行精确表示。当程序不完整或格式错误时,语法树还会表示源代码中的错误,通过在语法树中表示被跳过或缺失的标记。
这使得语法树具有第二个属性。从解析器获取的语法树完全可逆地回到其解析的文本。从任何语法节点,都可以获取以该节点为根的子树的文本表示。这意味着语法树可以用作构建和编辑源代码的一种方式。通过创建一个树,实际上已经创建了等效的文本;通过编辑语法树,从对现有树的更改创建新的树,实际上是编辑了文本。
语法树的第三个属性是它们是不可变且线程安全的。这意味着一旦获取了一个树,它就是代码当前状态的快照,并且永远不会改变。这允许多个用户在不同线程中同时与相同的语法树交互,而无需进行锁定或复制。由于树是不可变的,不能直接对树进行修改,工厂方法通过创建树的其他快照来帮助创建和修改语法树。语法树在重用底层节点方面非常高效,因此可以快速重建新版本,并且占用很少的额外内存。
语法树实际上是一种树形数据结构,其中非终结结构元素作为父节点包含其他元素。每个语法树由节点、标记和文本附加信息组成。
语法节点(Syntax Nodes)
语法节点是语法树的主要元素之一。这些节点表示语法构造,例如声明、语句、子句和表达式。每个语法节点类别由一个派生自 SyntaxNode 的单独类表示。节点类的集合不可扩展。
所有的语法节点都是语法树中的非终结节点,这意味着它们始终有其他节点和标记作为子节点。作为另一个节点的子节点,每个节点都有一个可以通过 Parent 属性访问的父节点。由于节点和树是不可变的,节点的父节点永远不会改变。树的根节点具有空的父节点。
每个节点都有一个 ChildNodes 方法,它返回一个基于节点在源代码中的位置的顺序列表,包含的是子节点,不包含标记。每个节点还有一组 Descendant 方法,如 DescendantNodes、DescendantTokens 或 DescendantTrivia,表示根据该节点为根的子树中存在的所有节点、标记或附加信息的列表。
此外,每个语法节点子类通过强类型属性公开相同的子节点。例如,BinaryExpressionSyntax 节点类具有三个特定于二元运算符的附加属性:Left、OperatorToken和Right。Left 和 Right 的类型是 ExpressionSyntax,OperatorToken 的类型是 SyntaxToken。
某些语法节点具有可选的子节点。例如,IfStatementSyntax 具有可选的 ElseClauseSyntax。如果子节点不存在,该属性将返回 null 。
语法标记(Syntax Token)
语法标记是语言语法的终结符,表示代码的最小语法片段。它们永远不是其他节点或标记的父节点。语法标记由关键字、标识符、文字和标点符号组成。
为了提高效率,SyntaxToken 类型是CLR值类型。因此,与语法节点不同,只有一个结构用于表示所有类型的标记,其中包含根据所表示的标记类型具有不同含义的属性组合。
例如,整数文字标记表示一个数值。除了标记跨越的原始源文本之外,文字标记还有一个 Value 属性,告诉您精确的解码整数值。由于该属性可能是多个基本类型之一,因此它的类型为 Object。
ValueText 属性提供与 Value 属性相同的信息;但是,该属性的类型始终为 String。在C#源文本中,标识符可能包括 Unicode 转义字符,但转义序列本身的语法不被视为标识符名称的一部分。因此,尽管标记跨越的原始文本包含转义序列,但 ValueText 属性不包含它。相反,它包括由转义所表示的 Unicode 字符。
语法琐事(Syntax Trivia)
语法注释表示源文本中对于正常理解代码而言主要是无关紧要的部分,例如空格、注释和预处理指令。
由于注释不是正常语言语法的一部分,并且可以出现在任何两个标记之间的任何位置,所以它们不作为节点的子节点包含在语法树中。然而,由于在实现诸如重构等功能时它们很重要,并且为了与源文本保持完全一致,它们确实作为语法树的一部分存在。
您可以通过检查标记的 LeadingTrivia 或 TrailingTrivia 集合来访问注释。在解析源文本时,注释序列与标记关联起来。通常情况下,一个标记拥有在同一行上紧随其后的所有注释,直到下一个标记为止。在该行之后的任何注释与下一个标记关联。源文件中的第一个标记获取所有初始注释,而文件中最后一个注释序列附加到文件结束标记上,否则文件结束标记的宽度为零。
与语法节点和标记不同,语法注释没有父节点。然而,由于它们是树的一部分,并且每个注释都与单个标记关联,您可以使用 Token 属性访问与之关联的标记。
与语法标记一样,注释是值类型。单个 SyntaxTrivia 类型用于描述各种注释。
跨度(Spans)
每个节点、标记或注释都知道它在源文本中的位置以及它所包含的字符数。文本位置表示为一个32位整数,它是基于零的 Unicode 字符索引。TextSpan 对象由起始位置和字符数两个整数表示。如果 TextSpan 的长度为零,它表示两个字符之间的位置。
每个节点都有两个 TextSpan 属性:Span 和 FullSpan。
Span属性是从节点子树中第一个标记的起始位置到最后一个标记的结束位置的文本跨度。这个跨度不包括任何前导或尾随注释。
FullSpan属性是包括节点正常跨度以及任何前导或尾随注释的文本跨度。
如下代码段:
if (x > 3)
{
|| // this is bad
|thrownew Exception("Not right.");|
// better exception?
||
}
在块内的语句节点具有由单竖线(|)表示的跨度。它包括字符"throw new Exception(“Not right.”);"。完整跨度由双竖线(||)表示。它包括与跨度相同的字符以及与前导和尾随注释相关联的字符。
种类(Kinds)
每个节点、标记或注释都有一个 RawKind 属性,类型为 System.Int32,用于标识表示的确切语法元素。该值可以转换为特定于语言的枚举;每种语言,C#或VB,都有一个单独的 SyntaxKind 枚举,列出了语法中所有可能的节点、标记和注释元素。可以通过访问 CSharpSyntaxKind() 或 VisualBasicSyntaxKind() 扩展方法来自动进行这种转换。
RawKind 属性可以轻松区分共享同一节点类的语法节点类型。对于标记和注释,这个属性是区分一个元素与另一个元素的唯一方式。
例如,一个 BinaryExpressionSyntax 类具有 Left、OperatorToken 和 Right 作为子节点。Kind 属性区分是 AddExpression、SubtractExpression 还是 MultiplyExpression 类型的语法节点。
错误(Error)
即使源代码包含语法错误,也会生成一个完整的语法树,可以循环转换回源代码。当解析器遇到不符合语言定义语法的代码时,它会使用两种技术之一来创建语法树。
首先,如果解析器期望某种类型的标记,但没有找到它,它可以在预期的位置将一个缺失的标记插入到语法树中。缺失的标记表示实际期望的标记,但它的范围为空,它的 IsMissing 属性返回 true。
其次,解析器可能会跳过标记,直到找到可以继续解析的标记为止。在这种情况下,被跳过的标记将作为一个带有 SkippedTokens 类型的注释节点附加到语法树中。
使用语义
语法树代表源代码的词法和语法结构。尽管仅凭这些信息就足以描述源代码中的所有声明和逻辑,但它并不足以确定正在引用的内容。
例如,许多具有相同名称的类型、字段、方法和局部变量可能分散在源代码中。尽管每个标识符都是唯一不同的,但确定它实际引用的内容通常需要对语言规则有深入的了解。
源代码中有表示程序元素的部分,程序也可以引用先前编译的库,这些库打包在程序集文件中。虽然程序集没有可用的源代码,因此没有语法节点或语法树,但程序仍然可以引用其中的元素。
除了源代码的语法模型外,语义模型还封装了语言规则,使您可以轻松区分这些元素。
汇编(Compilation)
编译是用于编译C#或Visual Basic程序的一切所需的表示,其中包括所有的程序集引用、编译器选项和源文件。
由于所有这些信息都在一个地方,因此可以更详细地描述源代码中包含的元素。编译将每个声明的类型、成员或变量表示为符号。编译包含各种方法,可帮助您查找和关联在源代码中声明的符号或从程序集中作为元数据导入的符号。
与语法树类似,编译是不可变的。创建编译之后,您或其他人都无法对其进行更改。但是,您可以从现有编译创建一个新的编译,同时指定所做的更改。例如,您可以创建一个与现有编译在所有方面都相同的编译,只是可能包含一个额外的源文件或程序集引用。
符号(Symbols)
符号代表源代码声明的独立元素或作为元数据从程序集导入的元素。每个命名空间、类型、方法、属性、字段、事件、参数或局部变量都由一个符号表示。
Compilation 类型上的各种方法和属性帮助您查找符号。例如,您可以通过其常见的元数据名称查找已声明类型的符号。您还可以将整个符号表作为以全局命名空间为根的符号树进行访问。
符号还包含了编译器从源代码或元数据中确定的其他信息,例如其他引用的符号。每种符号类型都由从 ISymbol 派生的单独接口表示,每个接口都具有自己的方法和属性,详细描述了编译器收集的信息。许多这些属性直接引用其他符号。例如,IMethodSymbol 类的 ReturnType 属性告诉您方法声明引用的实际类型符号。
符号在源代码和元数据之间提供了命名空间、类型和成员的共同表示。例如,源代码中声明的方法和从元数据导入的方法都由具有相同属性的 IMethodSymbol 表示。
符号在概念上类似于由 System.Reflection API 表示的 CLR 类型系统,但它们更丰富,因为它们建模的不仅仅是类型。命名空间、局部变量和标签都是符号。此外,符号是语言概念的表示,而不是 CLR 概念。它们有很多重叠之处,但也有许多有意义的区别。例如,C# 或 Visual Basic 中的迭代器方法是一个单一的符号。然而,当迭代器方法被翻译为 CLR 元数据时,它是一个类型和多个方法。
语义模型(Semantic Model)
语义模型表示单个源文件的所有语义信息。您可以使用它来发现以下内容:
-
源代码中特定位置引用的符号。 -
任何表达式的结果类型。 -
所有诊断信息,包括错误和警告。 -
变量在源代码区域中的流动情况。 -
更加推测性问题的答案。
使用工作区
工作区层是对整个解决方案进行代码分析和重构的起点。在该层中,工作区 API 帮助您将解决方案中所有项目的信息组织成单一的对象模型,为您提供直接访问编译器层对象模型(如源代码文本、语法树、语义模型和编译)的能力,无需解析文件、配置选项或管理项目间的依赖关系。
像集成开发环境(IDE)这样的宿主环境会为您提供与打开的解决方案相对应的工作区。此外,也可以通过简单地加载解决方案文件在IDE之外使用这个模型。
工作区(Workspace)
工作区是将解决方案表示为项目集合的活动表示形式,每个项目都包含一组文档。工作区通常与宿主环境绑定在一起,宿主环境会随用户的输入或属性操作而不断变化。
工作区提供对解决方案的当前模型的访问。当宿主环境发生变化时,工作区会触发相应的事件,并更新CurrentSolution属性。例如,当用户在与源代码文档对应的文本编辑器中输入时,工作区使用事件发出信号,表示解决方案的整体模型已经发生了变化,同时指明哪个文档被修改。您可以通过分析新模型的正确性、突出显示重要区域或提出代码更改建议来对这些变化做出反应。
您还可以创建独立的工作区,与宿主环境分离或在没有宿主环境的应用程序中使用。
解决方案,项目和文档(Solutions, Projects and Documents)
尽管工作区在按键时可能会发生变化,但您可以与解决方案模型独立地进行操作。
解决方案是项目和文档的不可变模型。这意味着可以共享该模型而无需锁定或复制。一旦您从工作区的CurrentSolution属性获取解决方案实例,该实例将不会发生更改。然而,与语法树和编译类似,您可以通过基于现有解决方案和特定更改构建新实例来修改解决方案。要使工作区反映您的更改,必须显式将更改后的解决方案应用回工作区。
项目是整体不可变解决方案模型的一部分。它代表所有源代码文档、解析和编译选项以及程序集和项目之间的引用。通过项目,您可以访问相应的编译,而无需确定项目依赖项或解析任何源文件。
文档也是整体不可变解决方案模型的一部分。文档表示单个源文件,您可以从中访问文件的文本、语法树和语义模型。
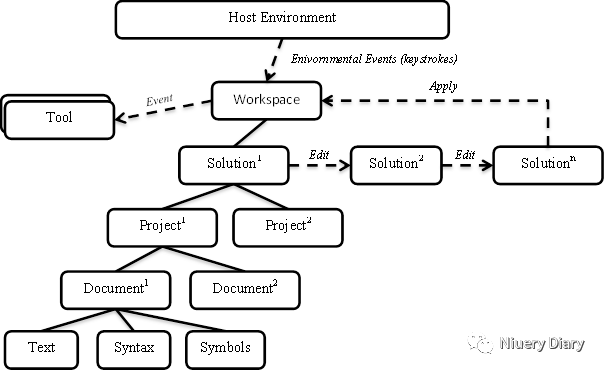
以下图表显示了工作区与宿主环境、工具之间的关系以及如何进行编辑。
总结
Roslyn 提供了一套编译器 API 和工作区 API,可以提供有关您的源代码的丰富信息,并与 C# 和 Visual Basic 语言完全兼容。将编译器作为平台的转变极大降低了创建以代码为重点的工具和应用程序的门槛。它在元编程、代码生成和转换、C# 和 VB 语言的交互使用以及将 C# 和 VB 嵌入领域特定语言等领域创造了许多创新机会。
参考https://github.com/dotnet/roslyn/blob/main/docs/wiki/Roslyn-Overview.md
