一、Index Template与Dynamic Template的概念
1、Index Template:它是用来根据提前设定的Mappings和Settings,并按照一定的规则,自动匹配到新创建的索引上。
1)模板仅是一个索引被创建时才会起作用,修改模板并不会影响已创建的索引;
2)可以设定多个索引模板,这些设置会被merge在一起;
3)通过指定order的数值,控制merge的过程;.
2、Index Template的工作方式如下:
当一个索引被创建时,会执行如下操作:
1)应用ElasticSearch默认的Mappings和Settings;
2)应用order数值低的Index Template中的设定;
3)应用order数值高的Index Template中的设定,之前的设定会被覆盖;
4)创建索引时,用户此时进一步指定了索引的Mappings和Settings,那么覆盖之前模板中的设定;
3、Dynamic Template:根据ElasticSearch识别的数据类型,结合字段名称,动态设定字段类型。
1)例如:所有的字符串类型可以设定成keyword,或者关闭keyword字段;
2)例如:凡是Is开头的字段都设置成Boolean;
3)例如:凡是Long开头的都设置成Long;
如下图所示:

Dynamic Template是定义在索引的Mappings中的,有一个模板名称,匹配规则是一个数组,同时可以将符合规则的字段进行Mapping。
二、Index Template与Dynamic Template使用
1、Index Template
1)通过创建一个dynamic mapping的索引,会发现日期类型推断成功,而数值类型被推断成text类型。 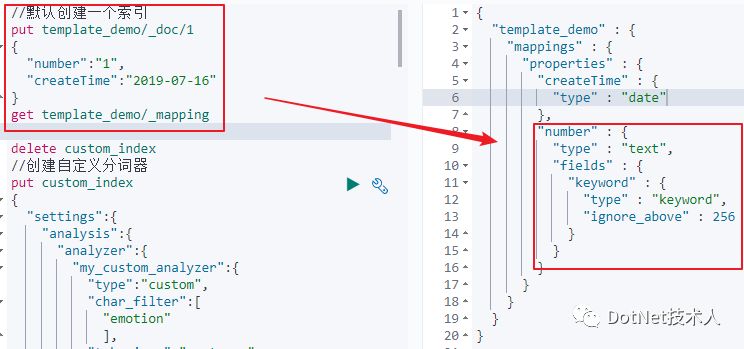
2)创建一个可以识别以test字符开头的索引模板,同时将日期识别设置为false,将数值识别设置为true。会发现日期会推断为text类型,数值类型推断正常。 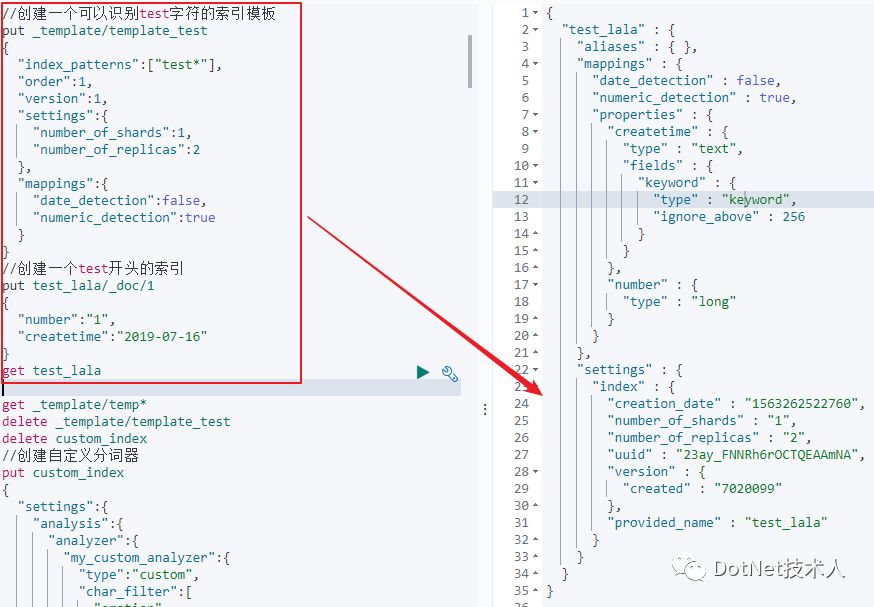
3)在创建索引时,设置settings的值,会覆盖模板设置信息。 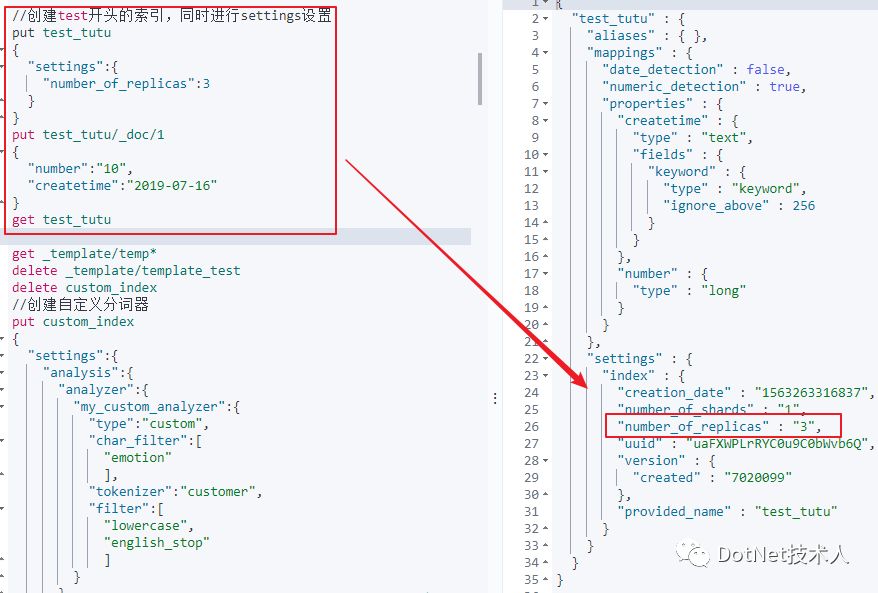
2、Dynamic Template
创建的索引进行mappings设置 
通过对mapping信息的读取可以发现,is开头的字段是boolean类型,duty字段是keyword类型,匹配name开头的字段,将信息可以copy_to到fullname字段中,不匹配middle后缀的字段信息。 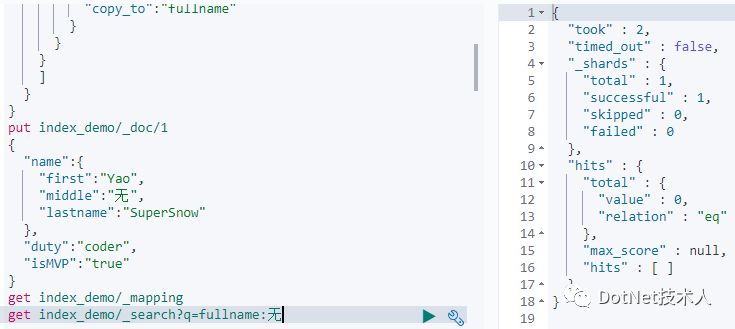
当对fullname字段搜索关于middle字段的信息时,搜索不到结果,当搜索first或者lastname时,可以搜索到结果。 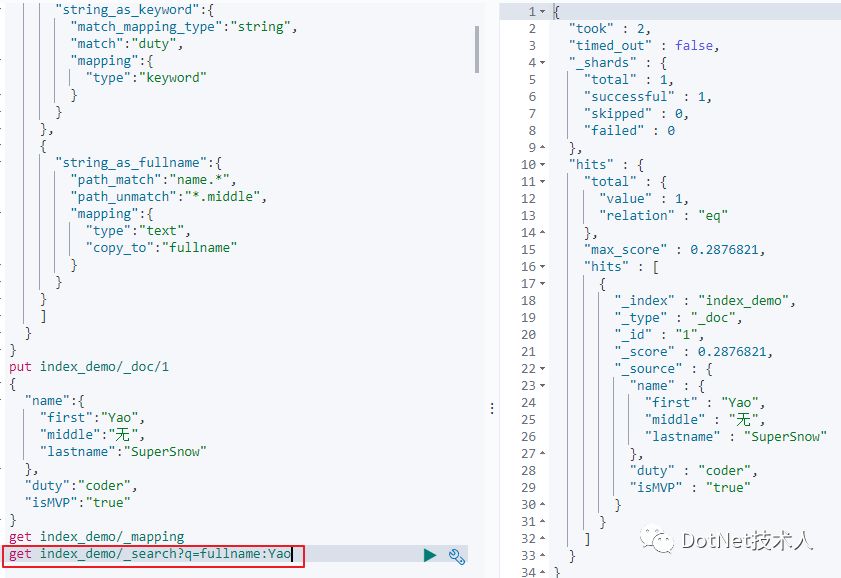
三、聚合的说明(Aggregation)
1、ElasticSearch聚合的优势
1)ElasticSearch除了搜索外,还提供了针对ElasticSearch数据进行统计分析的功能;
相对于Hadoop而言,ElasticSearch在这方面实时性高,比Hadoop的T+1更及时。
2)通过聚合,会得到一个数据的概览,这样就可以分析和总结全套的数据,而不是仅仅能寻找单个文档;
3)易用性,只需要一条语句,就可以从ElasticSearch中得到分析结果,从而避免在客户端实现分析逻辑;
2、聚合的分类
1)Bucket Aggregation:一些列满足特定条件的文档集合,其相当于SQL中的Group By;
2)Metric Aggregation:一些数学运算,可以对文档字段进行统计分析;
其相当于SQL中对于字段进行运算的函数,如Sum、Count等。它除了可以在字段上进行计算,还可以在脚本产生的结果上进行计算。
大多数Metric是数学计算,输出一个值,如:min/max/sum/avg/cardinality。
部分支持输出多个值,如:stats/percentiles/percentile_ranks。
3)Pipeline Aggregation:对其他的聚合结果进行二次聚合;
4)Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵;
3、聚合的使用
1)Bucket Aggregation 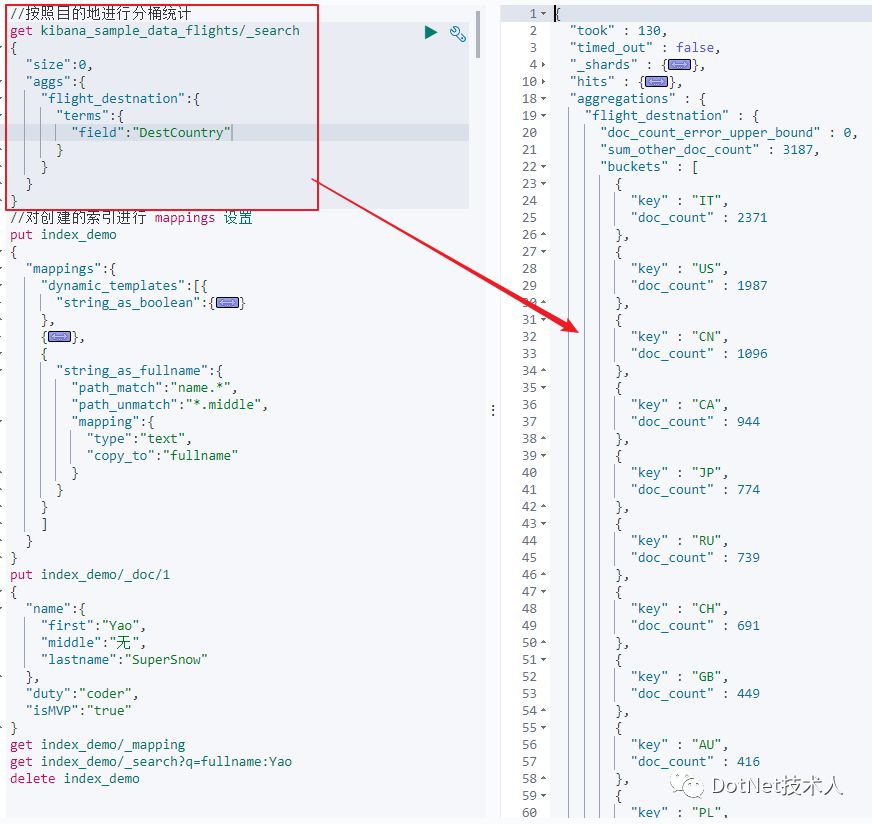
2)Metric Aggregation 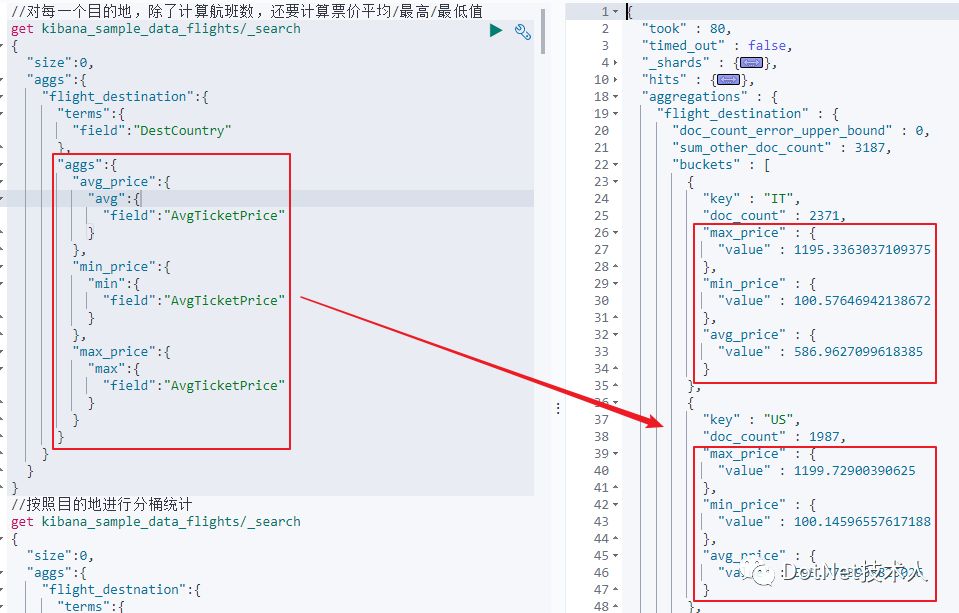
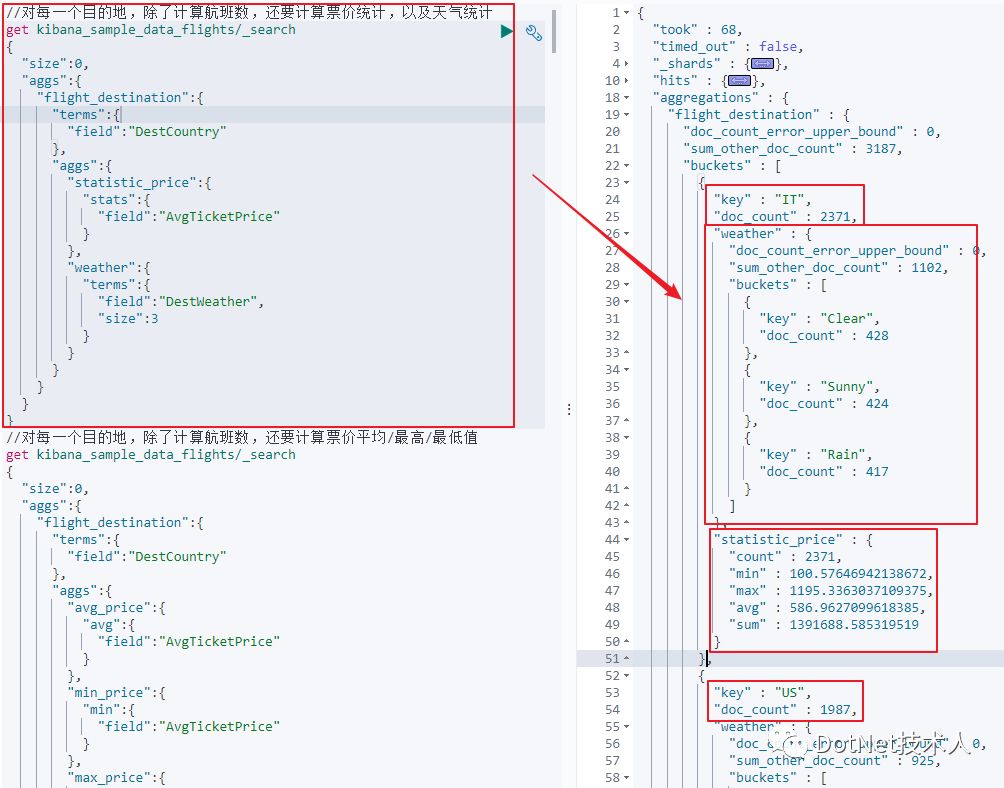
注意:在做聚合分析时,应将aggs前面的size设置为0,否则会返回查询结果,而不是聚合结果。如果写成20,聚合结果也能统计出来,只是在查询结果的后面。
