1前言
上一篇文章介绍了几个开源LLM的环境搭建和本地部署,在使用ChatGPT接口或者自己本地部署的LLM大模型的时候,经常会遇到这几个参数,本文简单介绍一下~
-
temperature -
top_p -
top_k
关于LLM
上一篇也有介绍过,这次看到一个不错的图.
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.
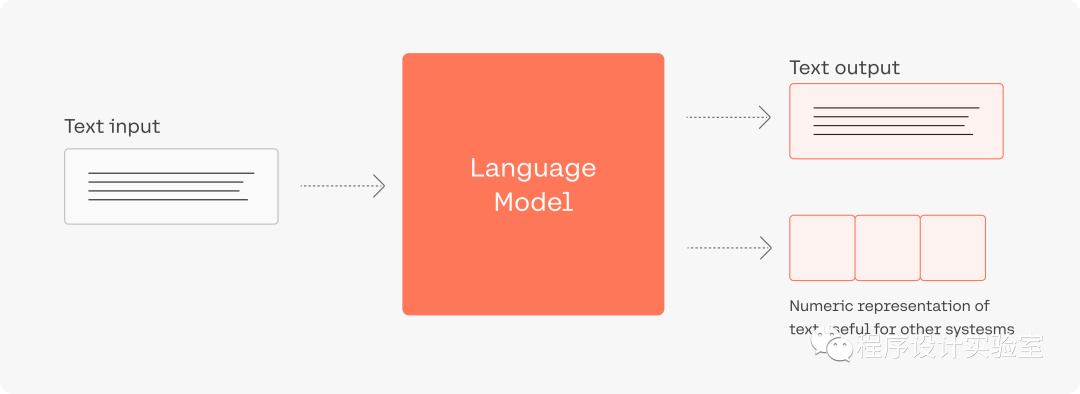
LLM看似很神奇,但本质还是一个概率问题,神经网络根据输入的文本,从预训练的模型里面生成一堆候选词,选择概率高的作为输出,上面这三个参数,都是跟采样有关(也就是要如何从候选词里选择输出)。
2temperature
用于控制模型输出的结果的随机性,这个值越大随机性越大。一般我们多次输入相同的prompt之后,模型的每次输出都不一样。
-
设置为 0,对每个prompt都生成固定的输出 -
较低的值,输出更集中,更有确定性 -
较高的值,输出更随机(更有创意
