在之前的篇章中,我们已经了解到了Stable Diffustion可以使用在线平台生成图片,但是提供的平台要么是收费,要么是模型受限,又或者生成效果不理想,总之受限瓶颈大,出于考虑到因为没有生成数量的限制,不用花钱,生成时间快,不用排队,自由度高,插件丰富,功能众多,可以调试和个性化的地方也更多,就决定将AI绘画工具部署到本地,这样我们就可以随意生成。.
Stable Diffusion也提供开源的Stable Diffusion WebUI,供用户自行部署使用。
在前面的几个篇章中,也分享了本地系统下如何进行安装。
具体内容可查看:
安装完Stable Diffusion后,我们就可以愉快的玩耍了。

Part1了解
要在实际工作中应用 AI 绘画,需要解决两个关键问题,分别是:图像的精准控制和图像的风格控制。

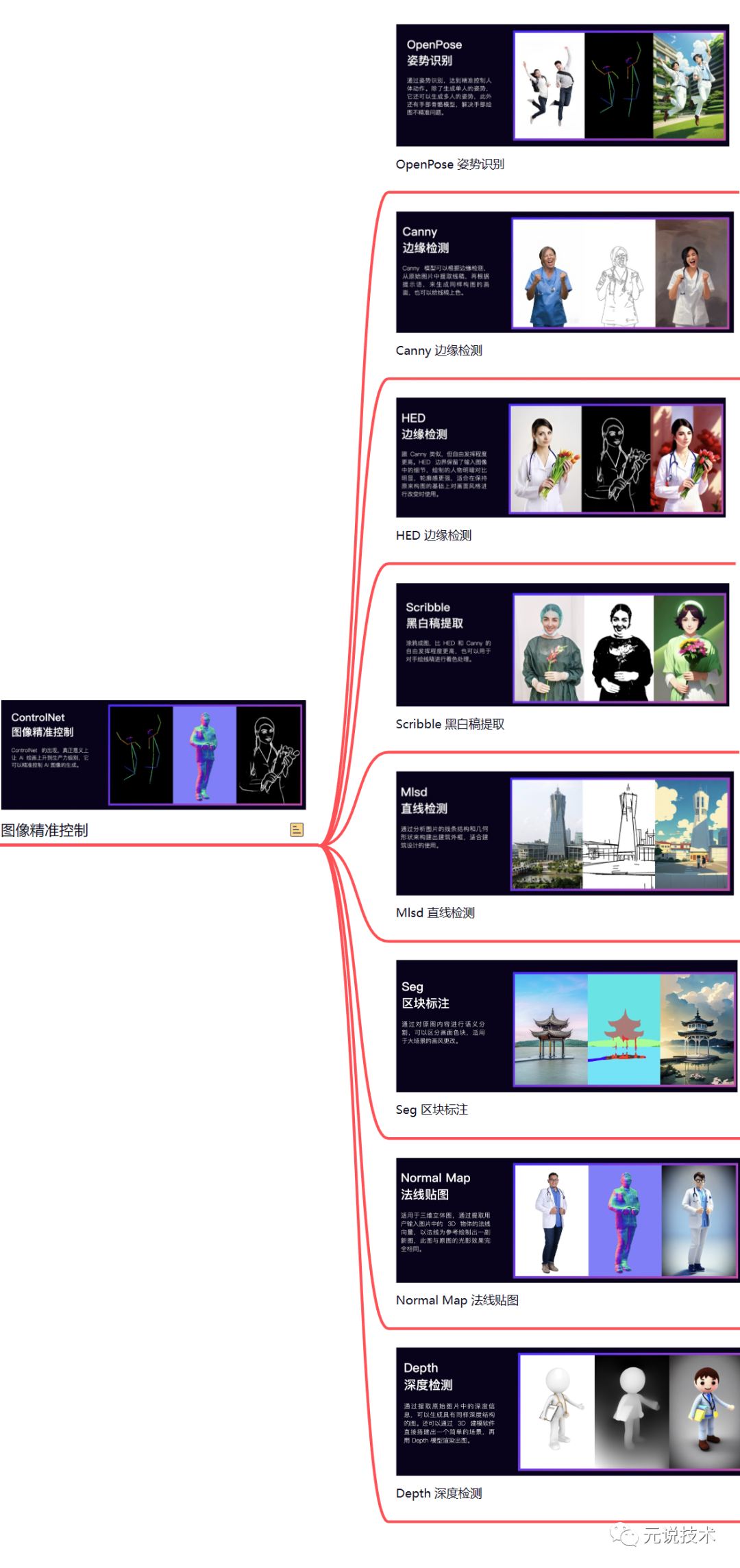
图像精准控制
图像精准控制推荐使用 Stable Diffusion 的 ControlNet 插件。在 ControlNet 出现之前,AI 绘画更像开盲盒,在图像生成前,你永远都不知道它会是一张怎样的图。ControlNet 的出现,真正意义上让 AI 绘画上升到生产力级别。简单来说 ControlNet 它可以精准控制 AI 图像的生成。
ControlNet 主要有 8 个应用模型:OpenPose、Canny、HED、Scribble、Mlsd、Seg、Normal Map、Depth
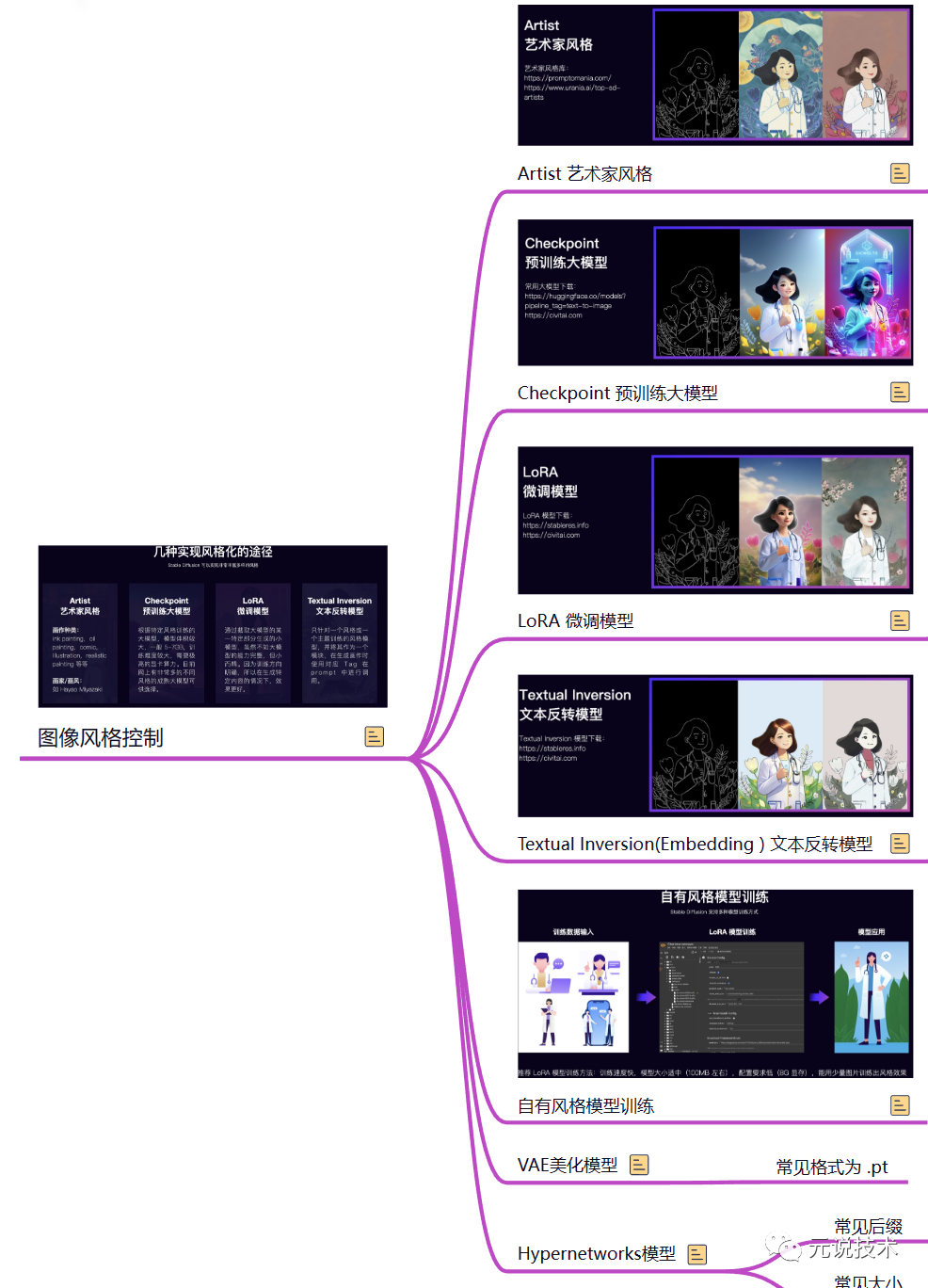
图像风格控制
Stable Diffusion 实现图像风格化的途径主要有以下几种:Artist 艺术家风格、Checkpoint 预训练大模型、LoRA 微调模型、Textual Inversion 文本反转模型、VAE美化模型、Hypernetworks模型
当然,可以将上面的模型可以分为两大类:大模型,小模型。
大模型:特指标准的 latent-diffusion 模型。拥有完整的 TextEncoder、U-Net、VAE。
小模型:用于微调大模型的小模型,由于想要炼制、微调(finetune)大模型十分困难,需要好显卡、算力,所以更多的人选择去炼制小型模型。这些小型模型通过作用在大模型的不同部分,来简单的修改大模型,从而达到目的。常见为:Textual inversion (常说的Embedding模型)、Hypernetwork模型、LoRA模型。
思维导图地址:https://www.processon.com/view/link/6442a2980fb07e723416ceb5 访问密码:ySFA
大模型
定义:官方提供的模型已支持2.1版,特定风格训练的大模型,模型风格强大。但同时训练强度大,在C站上也提供了基于官方进行训练后的模型包,提供下载。
常见后缀:ckpt、safetensors 。
常见大小:2G-7G
存放路径:
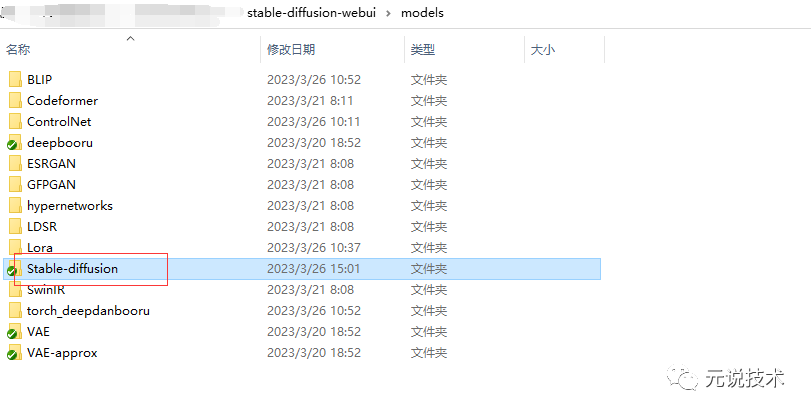
显示效果:

VAE模型
定义:可以理解为滤镜,选择了VAE就像是给图片套上了一层滤镜,会改变图片原有的颜色风格;一般默认是无,而且有些大模型中会自带VAE。
常见后缀:ckpt、pt。
存放路径:
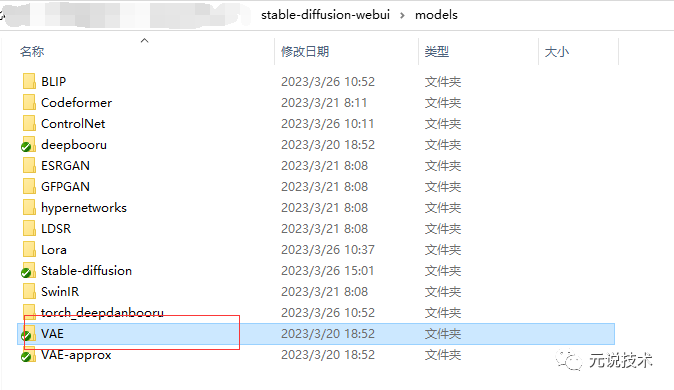
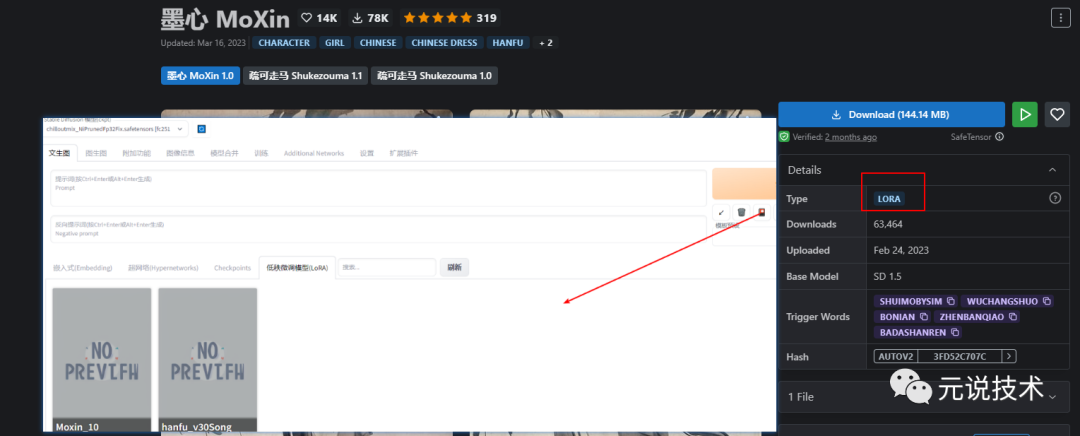
Lora模型
定义:用于微调大模型的小模型,选择小型模型。通过其作用在大模型的不同部分,来简单的修改大模型。因此训练方向明确,在生成特定内容的情况下,效果也会更好。
常见后缀:ckpt、safetensors 、pt
常见大小:8mb~144mb不等
存放路径:
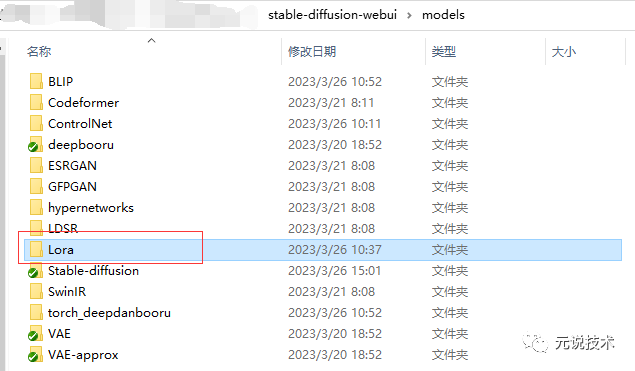
显示效果:
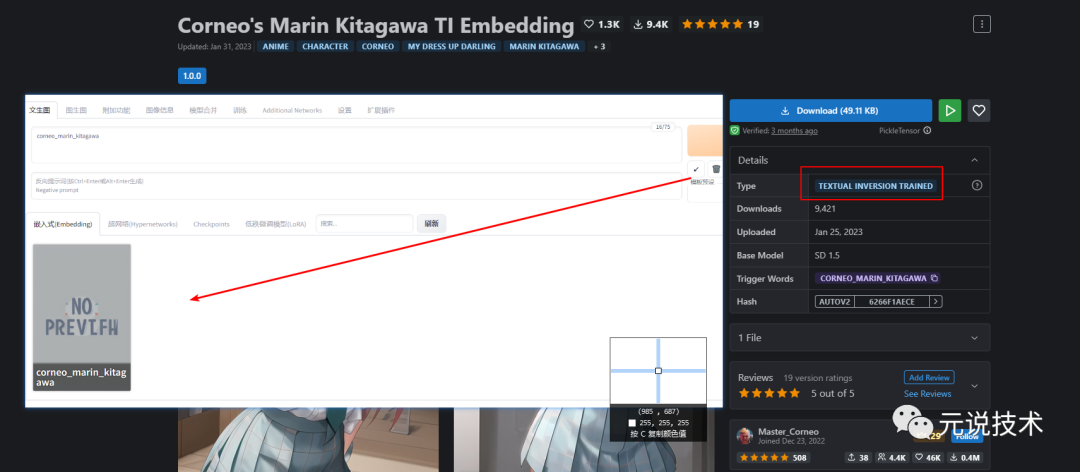
Embeddings模型
定义:通过角色训练产出,能够让你的主模型识别某个指定的角色,因为你的主模型不可能每个角色都认识,通过文件名来触发。
常见后缀:pt。
常见大小:几十KB
存放路径:
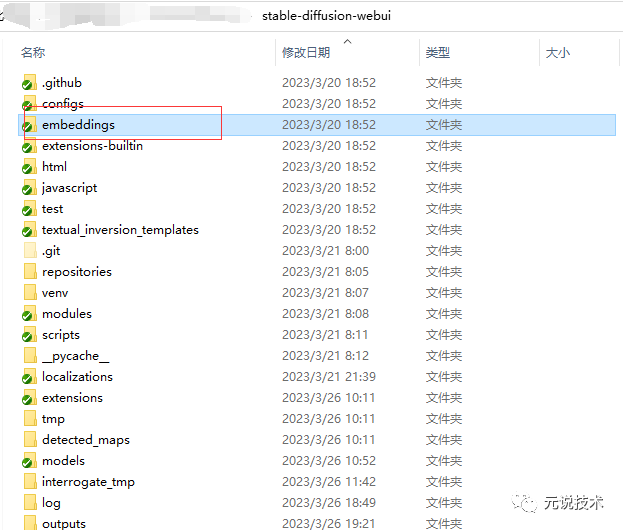
显示效果:
Hypernetworks模型
定义:通过画风训练产生,能够指定特定的画风模型
常见后缀:pt
常见大小: 几十KB
存放路径:
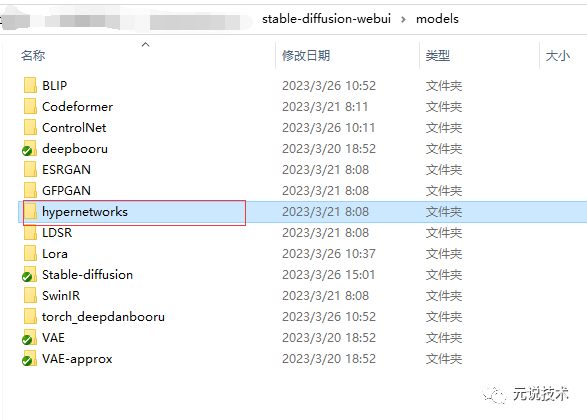
显示效果:
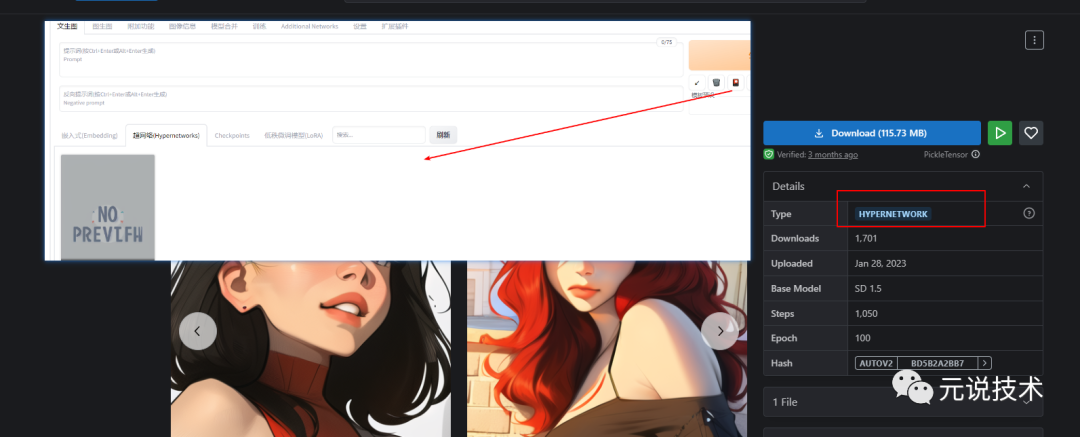
Part2使用
图像精准控制
安装完 Stable Diffusion WebUI 后,我们再安装 ControlNet 扩展,以便进行图像的精准控制,如让AI精准确定任务姿势和肢体细节,就需要安装这个插件
ControlNet 插件
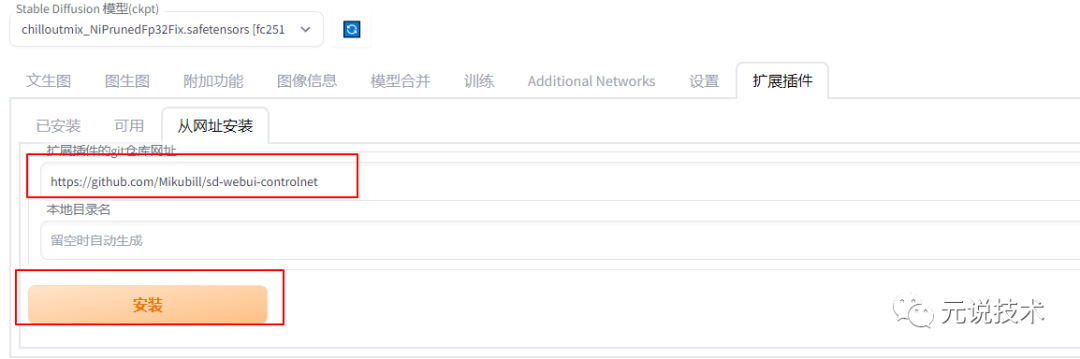
打开stable diffusion webui,进入"扩展插件"选项卡
点击"从网址安装",注意"扩展插件的git仓库网址"下方的输入框
粘贴或输入本Git仓库地址 https://github.com/Mikubill/sd-webui-controlnet
点击下方的黄色按钮"安装"即可完成安装,然后重启WebUI(点击"从网址安装"左方的"已安装",然后点击黄色按钮"应用并重启用户界面"
ControlNet 模型
安装完ControlNet插件之后,还需要下载特定的模型,不然在使用插件中,选中模型会是空白的。不同的模型对应的不同的功能。
这里推荐大型的预训练模型,打开模型下载页面 https://huggingface.co/lllyasviel/ControlNet/tree/main
将 annotator 目录中的人体检测预处理模型 body_pose_model.pth 和 hand_pose_model.pth 下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/openpose 目录。
将深度图模型 dpt_hybrid-midas-501f0c75.pt 下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/midas 目录
将 models 目录中的文件下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/models 目录
重启 WebUI 即可使用 ControlNet
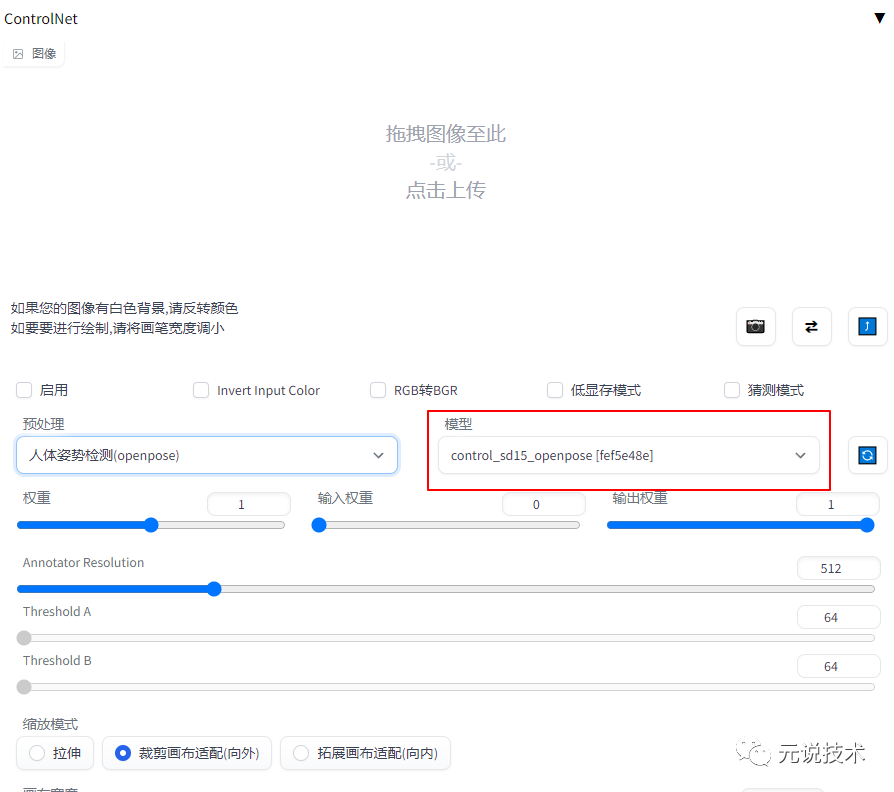
现在就可以在模型中进行切换选择
这里下载的模型可能会很大,当然了,你也可以下载一些压缩模型或第三方模型。
如:https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
图像风格控制
获取模型
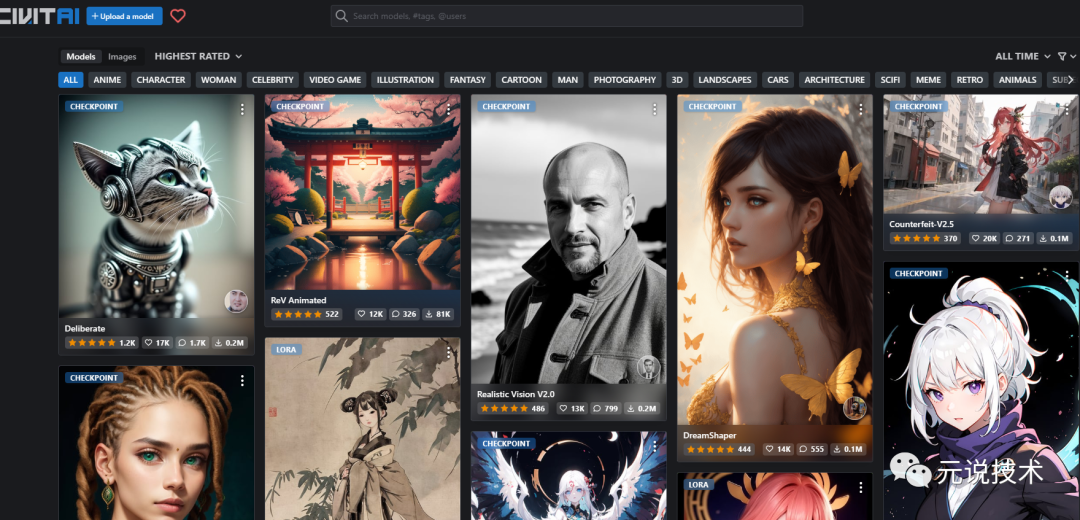
在上一篇中,可以通过社区平台获取到自己想要的模型。
https://civitai.com/
首先,根据我们之前分享的社区模型平台,收集了大量的创作者的多个模型。同时社区中还提供对应的关键词和评论以及多张带有提示的图像, 供用户下载使用。
这里我们找到自己想要生成的画风图片,查看详情,找到对应的下载包和模型。
应用
这里以hanfu 汉服lora包为例。
-
下载lora包,并放到指定文件夹
https://civitai.com/models/15365/hanfu
右上角点击download下载此Lora包。(一般几十到几百MB),下载好后,放在你电脑的stable-diffusion-webui > models > Lora文件夹下面。
-
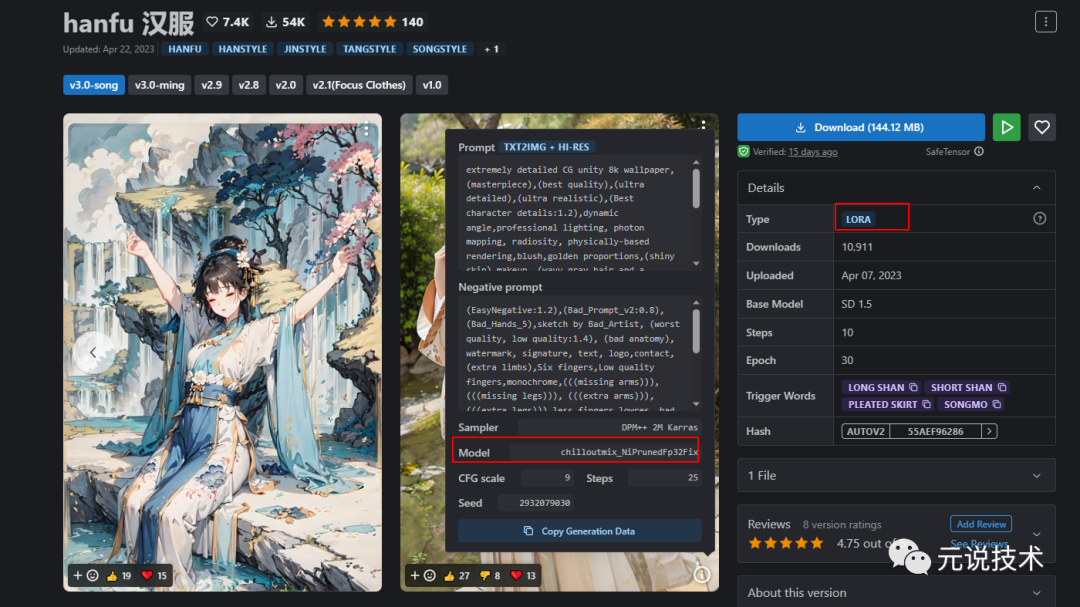
lora包网页,示例图片点击右下角的圈圈感叹号,查看生成信息。
提供了对应的Prompt、Sampler、Model、Seed等信息
-
找到model行,了解到这个lora包还需要使用
chilloutmix_NiPrunedFp32Fix模型 -
下载模型,并放到指定文件夹
接着我们把这个模型下载下来,并放在stable-diffusion-webui>models>Stable-diffusion文件夹下面
https://civitai.com/models/6424/chilloutmix
切换模型
-
启动stable diffusion webui
-
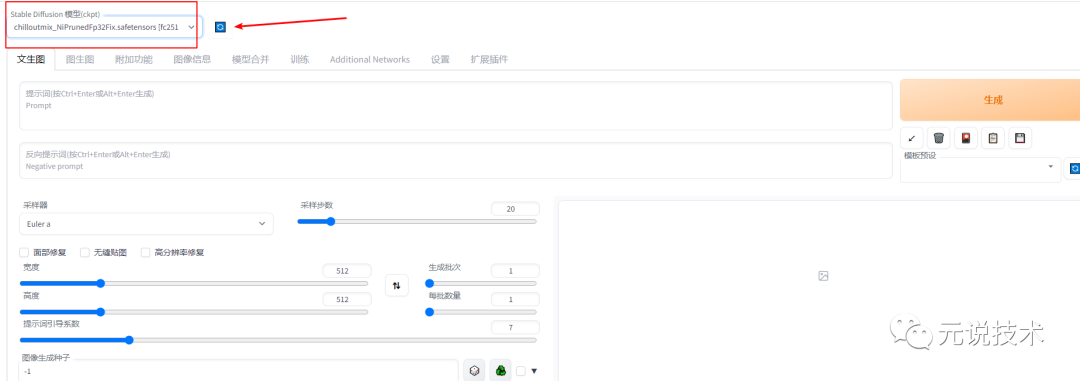
切换模型
先点击左上角的刷新按钮,接着点击左上角的向下箭头,找到你刚刚下载的chilloutmix_NiPrunedFp32Fix.safetensors模型,选中它。
等待一分钟后,按f5刷新页面,如果左上角已经自动显示了chilloutmix_NiPrunedFp32Fix.safetensors字样,那么模型就切换成功了。
(注意,切换模型需要先提前完成下载模型,并放到的指定文件夹)
生成图像
-
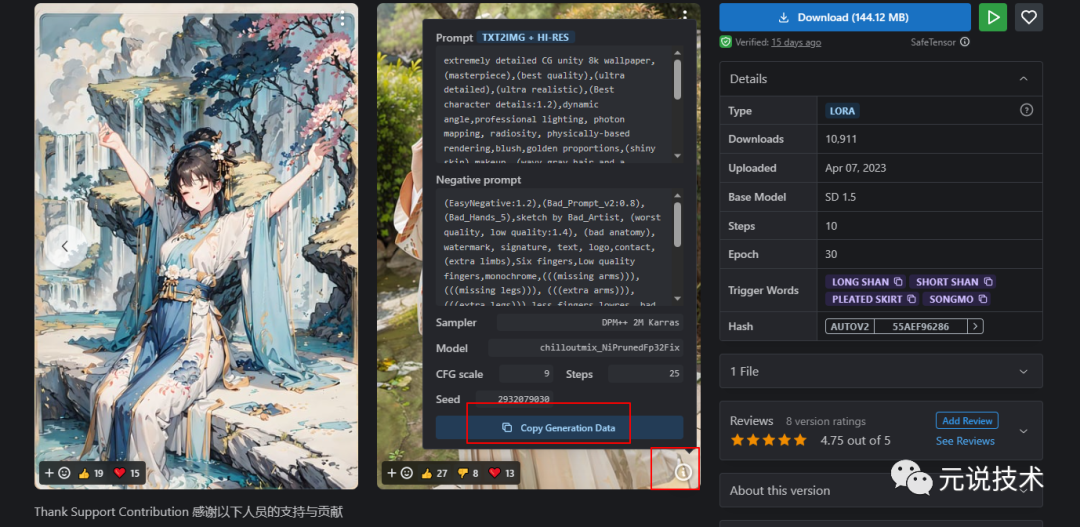
浏览器回到刚刚的那个hanfu 汉服网页,点开示例图片右下角的感叹号,点击copy generation data 按钮
https://civitai.com/models/15365/hanfu
-
在stable diffusion webui的 prompt输入框里面,Ctrl + V ,粘贴刚刚复制的内容后,接着点击Generate下方的“左下箭头”。
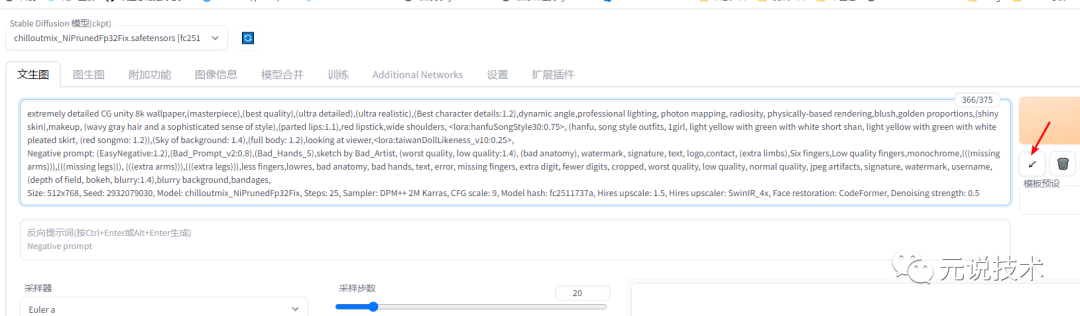
这时候,你会发现,刚才的prompt会自动填充下面的nagative prompt框,和下面的参数配置。
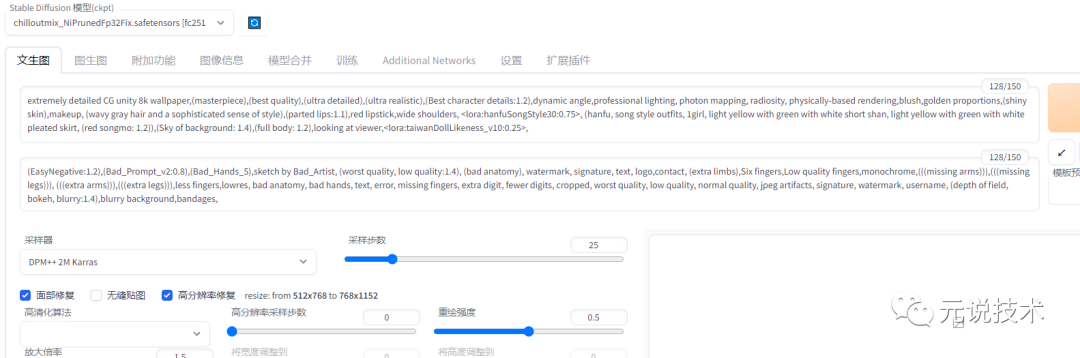
-
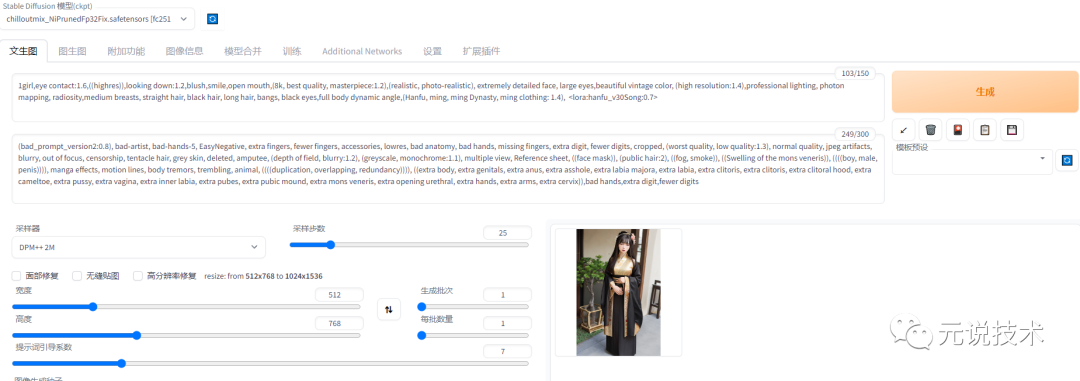
点击generate,开始生成图像。
-
等待图像生成完毕,然后右键点击生成的图像保存,或者点击图像下面的文件夹图标,进入文件夹查看生成的图像。
这期间可以自行的调整修改参数或者Lora模型,也可以进行混合模型试验,直到生成自己满意的作品
Part3欣赏

Part4附录
-
Stable Diffusion Webui:AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)
-
Stable Diffusion Webui 文档:Home · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com)
-
https://www.uisdc.com/stable-diffusion-2
-
